
Le fichier robots.txt : Pourquoi ? Comment ?
Les pages de votre site internet sont indexées par les robots des différents moteurs de recherche, comme par exemple GoogleBot de chez Google. Cependant, certaines pages et sections de votre site doivent certainement rester confidentielles. Je pense notamment à la section "/wp-admin" d'un site sous WordPress qui représente le Back-Office.
C'est là qu'intervient le fichier robots.txt ! Il vous permet de donner des directives aux robots concernant ce qu'ils ont le droit d'indexer ou non sur votre site.

Quand le fichier robots.txt est-il pris en compte ?
Avant de commencer l'aspiration de données et l'indexation de contenus, les robots iront vérifier s'il existe ou non un fichier robots.txt. Ce fichier doit être présent à la racine de votre site, sur votre serveur web, on y accédera via l'URL : http://www.votre-site.fr/robots.txt
Lorsque ce fichier existe, le robot lit les règles qu'il contient et suit les indications données. Au contraire, si le fichier n'existe pas le robot part du principe que rien ne lui est interdit (ce qui peut être dangereux !).
Et, quelle est la structure d'un robots.txt ?
La structure d'un robots.txt respecte la logique suivante : On indique les robots concernés puis à la suite on indique les règles qui s'appliquent aux robots précisés auparavant. C'est un peu comme si on sélectionnait un utilisateur et qu'on lui donne des droits, ce n'est que la façon d'écrire qui change...
Ah oui, au fait j'oubliais, il ne peut avoir qu'un seul fichier robots.txt sur votre site.
Passons à des exemples de robots.txt, ce sera plus explicite !
- Exemple n°1 :
User-agent: * Disallow: /wp-admin/
On autorise tous les User-agent - c'est-à-dire tous les robots - dans tous les répertoires sauf à l'exploration du contenu du répertoire "/wp-admin/". Pour rappel, il s'agit du répertoire de l'interface d'administration sous WordPress.
Ce que l'on peut retenir de cet exemple, c'est que l'on peut désigner tous les robots grâce à une étoile (*). De plus, on remarque que la directive Disallow est utilisée pour indiquer chaque répertoire à exclure, un par ligne.
- Exemple n°2 :
User-agent: * Disallow: /article
Ceci permettra d'empêcher l'indexation de différentes adresses telles que :
- http://www.votre-site.fr/article/
- http://www.votre-site.fr/article.html
En fait, dès que l'on retrouve la présence de la chaîne "/article".
- Exemple n°3 :
User-agent: * Disallow: /article/
Même exemple que précédemment, mais uniquement avec un slash en plus, de ce fait le lien "http://www.votre-site.fr/article.html" sera désormais indexé alors que ce n'était pas le cas dans l'exemple précédent. En ce qui concerne l'URL "http://www.votre-site.fr/article/" elle ne sera pas indexée non plus dans ce cas.
Vous remarquerez que l'on indique ce que l'on refuse grâce à "Disallow:". Sachez que comme Google le précise dans sa documentation, la directive "Allow:" permettra d'ajouter une autorisation, ce qui peut être utile pour autoriser un seul répertoire au sein d'une arborescence refusée.
"Disallow est une commande qui demande au user-agent de ne pas accéder à une URL particulière. Cependant, si vous souhaitez nous donner accès à une URL particulière qui est un répertoire enfant d'un répertoire parent non autorisé, vous pouvez utiliser le troisième mot clé Allow."
- Exemple n°4 :
User-agent: * Disallow:
On indique que l'on souhaite exclure aucune page de l'indexation, en fait, c'est comme s'il n'y avait pas de fichier robots.txt sur le serveur.
- Exemple n°5 :
User-agent: * Disallow:/
En indiquant simplement un slash, on indique que l'on exclut toutes les pages !
- Exemple n°6 :
User-agent: Googlebot-Image Disallow: /mon-icone.png
Si l'on souhaite empêcher l'indexation d'une image nommée "mon-icone.png" dans Google Images, on précisera auparavant que cela s'applique au bot Googlebot-Image.
- Exemple n°7 :
User-agent: * Disallow: /*.pdf$
Imaginons que vous avez des fichiers PDF sur votre site et que ne souhaitez pas les voir indexés, utilisez la directive ci-dessus pour appliquer le filtrage sur un type de fichier particulier. En ce qui concerne le caractère "$", il permet de bloquer toutes les URL qui se terminent d'une certaine manière.
- Exemple n°8 :
User-agent: * Disallow: /profil-*/
L'utilisation du caractère astérisque * permet d'indiquer "N'importe quelle séquence de caractères". Ce qui veut dire que tous les répertoires qui commencent par "profil-" seront bloqués grâce à la présence de l'astérisque.
Enfin, pour ceux qui souhaitent commenter le fichier robots.txt, utilisez un # en début de ligne pour ajouter une ligne commentaire.
Point important également, il faut savoir que les expressions sont sensibles à la casse. Soyez donc prudent dans l'utilisation des majuscules et minuscules dans la déclaration de vos règles.
Quelques robots connus...
- Googlebot-Image : Google Images
- Googlebot : Google
- Bingbot : Bing
- VoilaBot : Orange
- ExaBot : Exalead
Comment tester son fichier robots.txt ?
Pour tester ce fichier et voir si vos règles répondent à vos attentes, un outil est disponible dans les Outils pour Webmasters de Google.
Cet outil permet notamment de tester différentes URL et de voir si elles sont autorisées ou non à être indexées. Pour cela, vous pouvez également tester avec un bot Google en particulier.
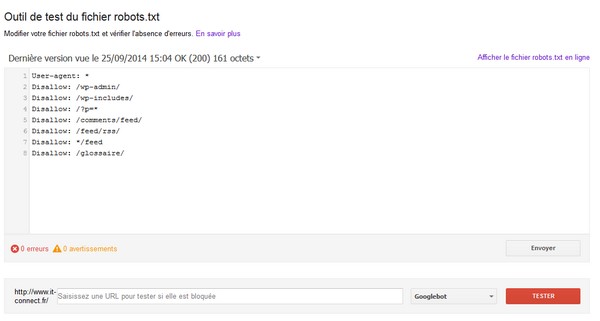
Un must pour vérifier son fichier robots.txt avant la mise en production, ne passez pas cette étape ! Ne jouez pas avec votre référencement !








merci pour toutes ces infos !!
bonne journée