

Centralisation des logs, un outil pour la sécurité
Sommaire
I. Présentation
Lorsque l'on entame la consolidation d'un système d'information, je pense que la première chose à faire est avant tout la centralisation des logs. Dans cet article, nous allons voir en quoi consiste la centralisation des logs, ce que cela apporte en matière de gestion et de sécurité et également des pistes d'outils à utiliser pour accomplir cette tâche.
La centralisation des logs est une opération simple à faire sur des systèmes d'information peu étendus (au niveau réseau comme au niveau géographique), cela s'avère plus complexe sur des SI de grande taille, mais c'est une opération à mener à tout prix pour éviter certains risques et avoir une vue réelle de l'état d'un système d'information.
II. Qu'est-ce que la centralisation des journaux d’événements (logs) ?
Un log, événement ou journal, est simplement la notification d'un événement d'une importance plus ou moins élevée envoyée par un service, un système, un élément réseau ou une application. Les journaux d’événement permettent en administration systèmes, réseaux et en sécurité de retracer les actions et la vie d'un système. Les logs ont un intérêt et une importance cruciale en informatique, car il s'agit là de savoir ce qu'il s'est passé sur un ensemble d'applications ou systèmes pour pouvoir, par exemple :
- Expliquer une erreur, un comportement anormal, un crash sur un service comme un service web;
- Retracer la vie d'un utilisateur, d'une application, d'un paquet sur un réseau sur les logs d'un proxy et des éléments réseau par exemple;
- Comprendre le fonctionnement d'une application, d'un protocole, d'un système comme les étapes de démarrage d'un service SSH sous Linux;
- Être notifié d'un comportement, d'une action, d'une modification tel qu'une extinction ou un démarrage système;
- etc.
Aujourd'hui, la grande majorité des systèmes, applications et éléments réseau produisent des logs. Dans la quasi-totalité des cas, les logs sont stockés de manière locale sur la machine :
- Les journaux d’événements sous Windows stockent par défaut les logs des OS Windows (Clients et serveurs) via l'observateur d’événement
- Le fameux dossier "/var/log" sous Linux qui stocke l'ensemble des logs systèmes et applicatifs sous Linux via rSysLog (mais pas que, cela dépend des distributions)
- sous Cisco, quelques messages de logs sont inscrits directement dans le terminal, mais le reste des logs n'est pas sauvegardé, faute de stockage
Dans ce cadre, la centralisation des logs consiste simplement à mettre sur un même système, une même plateforme, l'ensemble des logs des systèmes, applications et services des machines environnantes. On reprend alors le principe de la supervision, dont la surveillance des logs doit être une branche, qui consiste à centraliser les éléments de surveillance sur une plate-forme unique. On appellera cela un point unique de communication, ou point unique de contact (Single Point Of Contact - SPOC) pour l'analyse des logs. La centralisation de l'information permettra ici de mener plusieurs opérations qui iront toutes dans le sens de la sécurité et de la meilleure gestion du système d'information.
Clairement, pourquoi centraliser les logs ?
Communément, deux raisons répondent à cette interrogation :
- Avoir une vue d'ensemble d'éléments cruciaux à la bonne gestion d'un SI pour y mener des traitements tels que :
-
- IDS : Certains types d'IDS (Intrusion Detection System ou systèmes de détection d'intrusion) se servent des journaux d’événement pour détecter des comportements anormaux sur le réseau ou sur les systèmes surveillés. Ceux-ci n'utilisent donc pas l'écoute du réseau pour effectuer leur surveillance mais bien les logs, on appelle alors ces IDS des log-based IDS (IDS basé sur les logs). Des exemples connus de tels systèmes sont Fail2ban et DenyHosts par exemple.
- Forensic, plus largement l'analyse d'attaque ou d'intrusion : on peut décrire le forensic de la façon suivante : "c'est une méthode d'investigation matérielle ou virtuelle basée sur l'extraction de données brutes ou altérées de manière à construire une chronologie événementielle, à établir une logique séquentielle ou à reconstituer un ensemble cohérent de données pour en tirer une explication contextuelle. " (source : post d'un membre d'Hackademics). C'est une définition exacte dans le cadre qui nous intéresse même si les notions d'enquête et de moyen légal de récupération de données sont ici oubliées. Quoi qu'il en soit, les logs vont être d'une grande aide lorsque ceux-ci nous permettent de retracer le parcours, les actions et les dégâts d'un attaquant sur un ensemble de systèmes. Ceux-ci étant facilité d'abord parce que les logs sont centralisés, mais également, car ils sont exportés de la zone d'effet de l'attaquant qui a alors plus de difficulté à les supprimer pour effacer ses traces.
- Recherche / statistique : La centralisation des logs va permettre d'effectuer des recherches très précises sur l'activité de plusieurs systèmes tout en étant sur une machine. Les opérations de recherche et de statistique s'en trouvent donc facilitées, car tout est sur la même plate-forme.
- En cas de crash ou de suppression des logs
- Diagnostiquer un crash : Il peut être très utile de savoir précisément ce qu'il s'est passé lorsqu'un système devient complètement injoignable (après un crash sévère par exemple). Si les logs qui permettent de diagnostiquer la panne se trouvent sur ladite machine, ils sont difficilement atteignables (on peut toujours extraire les disques, les lires sur un autre périphérique, etc.). Dans le cas où les logs sont exportés sur une machine dont la disponibilité est assurée, il est alors possible de rapidement récupérer les derniers événements systèmes de la machine endommagée pour diagnostiquer plus facilement.
- Garantir la survie des logs à une suppression : Comme je l'ai rapidement expliqué en haut, une des étapes post-intrusion lors d'une attaque informatique est l'effacement des traces que le pirate a pu laisser. On passe alors, en partie, par la suppression des logs et historiques qui peuvent donner des indications sur les actions menées pendant l'intrusion et possiblement sur une identité réseau (IP, adresse MAC, OS, etc.). Lorsque les logs sont stockés en local, les logs qui sont supprimés sont alors difficilement récupérables, lorsqu'ils sont également envoyés sur une autre machine, il est possible de récupérer des informations. Notons que la suppression, ou perte, des logs peut également arriver dans d'autres contextes plus proches de la vie quotidienne d'un SI telle que la perte d'un disque, d'une partition dédiée aux logs, la mauvaise manipulation d'un administrateur systèmes pressé...
C'est en mon sens par là que devrait débuter la consolidation et la sécurisation d'un système d'information. La capacité à retrouver un événement même après une attaque ou un crash et à faire corréler un ensemble d’événements pour amener à la meilleure gestion des systèmes permet d'avoir un appui solide pour la prise de décision quant à l'évolution du SI, mais aussi par rapport aux éventuels problèmes présents, mais non découverts. Lorsque l'on regarde les choses en face, les logs sur les systèmes et OS ne sont ouverts que quand un problème bloquant intervient et qu'ils peuvent alors nous aider à débugger une situation. Le reste du temps, les logs ne sont lus que par les scripts et les outils d'archivage ou de suppression. Or un événement, surtout lorsqu'il a une criticité élevée, est quelque chose dont il faut s'occuper. Soit pour le corriger, soit pour au moins savoir l'expliquer et connaître l'impact qu'il y a derrière ces avertissements.
La centralisation des logs, lorsqu'elle est couplée à des outils d'analyse, de traitements, d'indexation et encore mieux, de graphage, permet d'avoir de toutes ces lignes d'information un ensemble cohérent de données qu'il est possible de corréler. Le fait de corréler les logs signifie simplement que l'on met en relation plusieurs événements de systèmes et d'application pour reconstituer une action plus générale. Les logs d'une synchronisation rsync qui coupe brutalement entre deux serveurs Linux peut par exemple être corrélé avec la coupure du service SSH sur une des deux machines, expliquée elle-même par une mauvaise manipulation de l'administrateur système qui aura également laissé des traces dans les journaux d’événement en ouvrant son terminal sur la machine en question... L'exemple est ici simplissime, la corrélation des logs permet le plus souvent de retracer les attaques et les intrusions, par exemple en effectuant une analyse comportementale d'un attaquant. Nous sommes alors sur un niveau de complexité bien plus élevé, que je ne saurais expliquer ici pour le moment 🙂 .
III. Centralisation des logs, un processus en plusieurs étapes
La centralisation n'est pas un processus qui se fait du jour au lendemain, sauf si vous avez la chance et la bonne idée d'y penser dès les premiers pas de votre SI. La plupart du temps, la centralisation des logs implique de réfléchir à plusieurs étapes de mise en place. Communication entre différents systèmes, parcours des paquets au travers différents réseaux pour arriver à une même cible, catégories/organisation à avoir, informations à exporter et informations à mettre de côté... Voyons les différentes étapes qui peuvent guider la mise en place d'une centralisation de logs dans un SI.
A. Faire produire les logs
La première chose à faire est bien entendu de faire en sorte que les logs méritant d'être lus soient produits. Sur Cisco par exemple, la production des logs n'est pas activée par défaut. Sur d'autres systèmes, seuls les logs "CRITICAL" et supérieurs sont sauvegardés. Il peut alors, en fonction de notre besoin, rehausser ou abaisser la criticité des logs qui sont produits.
Également, il est important de calibrer correctement la production de logs. Il faut savoir que plus un service, un système ou une application produit de logs, plus celle-ci va consommer des ressources. Il est par exemple généralement déconseillé, sur les services de base de données comme MySQL, de faire produire trop de logs. Ces services ont généralement besoin d'être contactés rapidement et il n'est pas toujours possible de leur fait produire autant de logs qu'on le voudrait, car cela ralentirait les délais de traitements et de calculs.
Il faut donc veiller à correctement définir ce que l'on souhaite voir, ce que l'on souhaite garder en local et ce que l'on souhaite envoyer sur un serveur de logs distant. Cela demande un certain travail et une vision globale du système d'information, car il est nécessaire d'effectuer cette tâche sur tous les systèmes et les applications qui en ont besoin, tout dépendra donc de la taille de votre système d'information.
B. Envoyer les logs sur une plateforme commune
Une fois que l'on sait exactement quoi envoyer et centraliser, il faut maintenant savoir l'envoyer sur la plate-forme destinée à recevoir ces logs. On passe alors également par une phase de réflexion au niveau de l'architecture et de la configuration nécessaire :
- Il faut bien évidemment auparavant avoir configuré et installé le système nécessaire à la bonne réception et au bon stockage de l'ensemble des logs envoyés. Pour avoir un exemple de technologie permettant de faire cela, j'ai rédigé il y a quelque temps sur mon blog technique un tutoriel sur la configuration du service Rsyslog sous Linux pour en faire un serveur de centralisation des logs : Centralisez vos logs avec Rsyslog
- On va ensuite devoir réfléchir au chemin qu'empruntent nos logs envoyés. En effet, les machines dans le LAN ne vont pas forcément poser problème. En revanche, les machines en DMZ ou sur des sites géographiquement éloignés peuvent poser quelques difficultés. On peut alors se poser différentes questions, est-il judicieux d'ouvrir le port permettant de laisser passer les flux nécessaires de la DMZ au LAN ? Le lien entre mon datacenter et mes sites distants sera-t-il suffisant ? N'est il pas plus logique de travailler avec des serveurs de logs répartis par sites géographiques ? La réponse à ces questions n'est pas l'objet de cet article et dépendra de toute façon de votre système d'information, à vous d'en juger donc !
- Il faut également avoir une réflexion sur la configuration et les ressources de la machine de centralisation des logs en elle-même, quelle sera la technologie et l'espace de stockage adéquat et suffisant ? Plusieurs cartes réseau seront-elles nécessaires ? Quelle sécurité mettre en place sur ce serveur ?
C. Analyser, filtrer et organiser les logs
Maintenant que nos logs sont arrivés à destination et qu'ils sont dans un endroit sûr, il faut savoir quoi faire de ces journaux d’événements. Quand un log va arriver sur notre serveur de centralisation des logs, il va systématiquement devoir passer par différentes étapes.
Nous allons d'abord devoir trier ce flux d'information, on peut par exemple créer un répertoire par machine puis un fichier par service, ou alors un fichier par service dans lequel on pourra distinguer la provenance des lignes de logs par le nom de la machine l'ayant produit. L'organisation et le tri des logs se fait de toute manière par le service qui gérera sa réception (Rsyslog par exemple sous Linux).
Une fois que nos logs sont dans les bonnes étagères, il va alors être possible de les lire, les examiner, corriger leur position éventuellement pour arriver à l'objectif final de la centralisation des logs : la production d'un outil utile à la bonne gestion du système d'information.
D. Grapher, Rapporter, Alerter : L'apport en sécurité
La bonne gestion des logs dans notre serveur de centralisation des logs va permettre de produire différentes choses comme :
- Une fois que nos logs sont correctement organisés et que l'on peut faire des traitements dessus, on pourra par exemple dessiner des graphiques avec des outils spécialisés. Voici un exemple de rapport graphique produit par Kibana qui se base sur des logs :
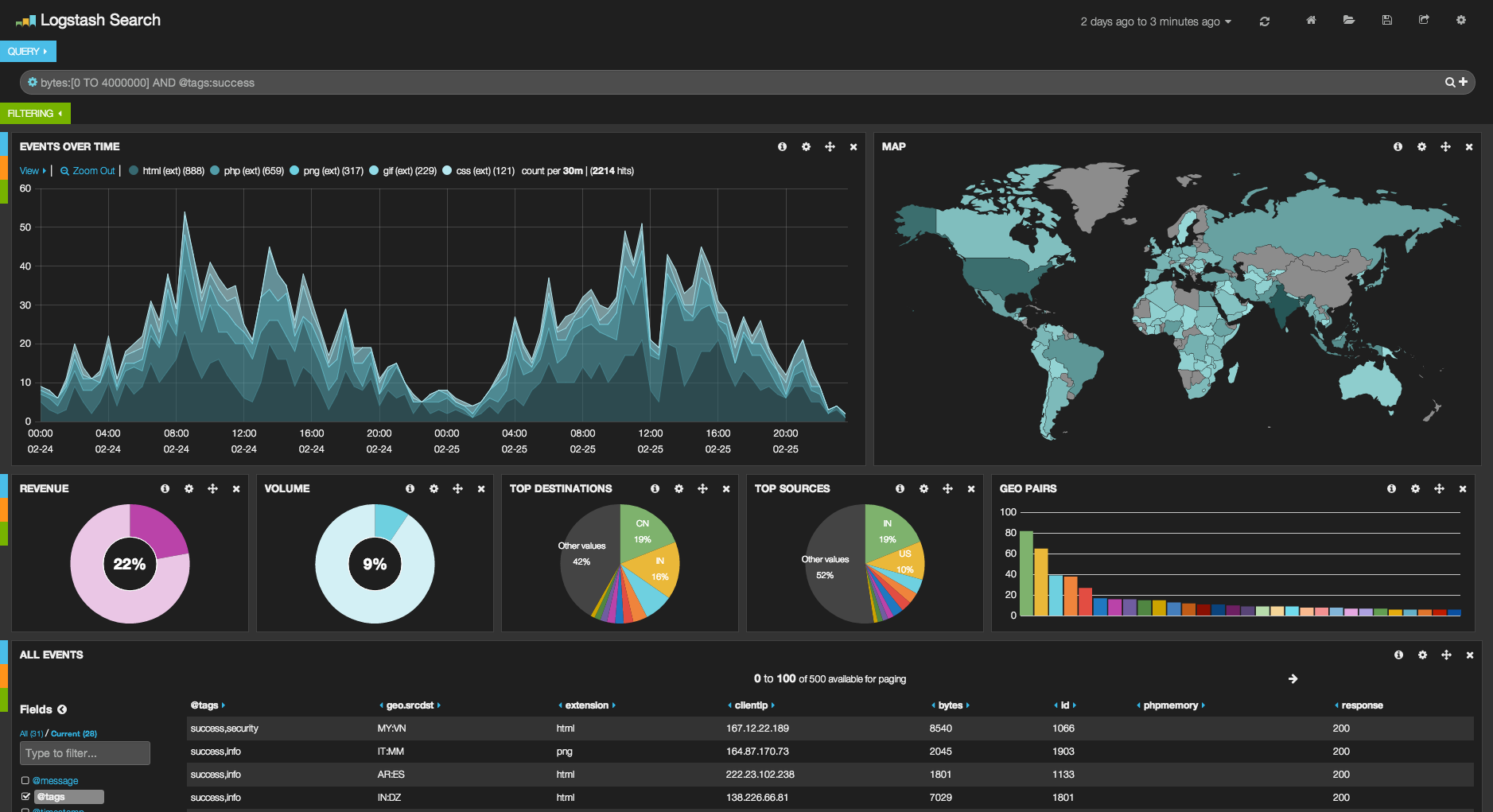
Les graphiques sont alors, comme dans la supervision, un élément pour avoir rapidement une vue de l'état d'un ou plusieurs systèmes. On va par exemple pouvoir grapher en direct le taux d'erreur 404 relevé sur l'ensemble de nos serveurs web et ainsi détecter un pic qui pourrait relever un problème plus grave. Également, il sera possible de grapher les échecs d'authentification SSH et, pourquoi pas, détecter une brute force via un pic représenté dans les graphiques. Outre des observations sur le coup, on pourra également, avec des données graphées, voir les tendances sur le long terme et ainsi mieux appréhender l'évolution d'un système ou d'un service.
- La centralisation des logs va également permettre leur intégration dans un système de supervision, on va pouvoir plus facilement détecter des comportements ou des logs anormaux par rapport à un comportement standard. Par exemple, une détection des événements anormaux, mettre en relation avec le service de supervision, corrélation d’événements.
- Mettre en place des actions de protection et de prévention du système d'information. Avec des logs centralisés, il sera possible d'effectuer une analyse en temps réel des journaux d’événements et cela de façon beaucoup plus simple, cela parce que les logs se situeront tous sur la même machine. L'utilisation des log-based IDS/IPS sera alors plus simple et plus efficace dans la protection du système d'information.
- Il est fréquent, en tant qu’administrateur système, de se faire envoyer des rapports par des scripts qui analysent les logs des machines par exemple. Avec des logs centralisés, on pourra avoir un rapport pour un ensemble/un groupe de machines plutôt que d'avoir un rapport individuel par machine. Cela, car tous les logs analysés se situeront sur la même machine.
IV. Pour commencer, quelques outils
Maintenant que nous avons vu en quoi consistait la centralisation des logs, voyons quelques outils qui sont généralement utilisés, soit pour la récolte, soit pour l'analyse des journaux d’événements centralisés :
- Fail2ban : Fail2ban est un outil que j'apprécie particulièrement, il s'agit d'un IDS/IPS basé sur les logs. Ils sont donc d'une importance capitale ici, car les logs produits vont permettre à Fail2ban de détecter certaines intrusions et ainsi déclencher des actions d'avertissement ou de protection (envoyer un mail, bannir une ip, etc.). Quelques tutoriels sur Fail2ban
- DenyHost : DenyHost reprend le même principe que Fail2ban, il se base sur les logs dans le fichier /var/log/auth.log des machines Linux pour détecter des tentatives de bruteforce sur le port SSH. Il n'est malheureusement retreint qu'au service SSH.
- Rsyslog : Rsyslog est ce qui permet de gérer les logs sur la plupart des machines Linux, il implémente le protocole syslog pour l'envoi de logs entre machines. C'est un outil à connaître lorsque l'on entreprend de centraliser des logs avec des machines sous Linux.
- Splunk : Il s'agit d'un outil d'indexation des journaux d’événements. Autrement dit, une fois les logs centralisés, Spunk va permettre d'effectuer des recherches facilement dans ses logs pour en extraire des données facilement exploitables.
- Snare : Snare est un outil pour Windows, il s'agit d'un service qui interagit avec le système Windows Event Log pour faciliter la gestion à distance et le transfert en temps réel des informations des journaux d'événements Windows.
- ELK : Il s'agit de la combinaison de trois logiciels : Elasticsearch en tant que moteur d'indexation, Logstash pour la collecte, l'analyse et le stockage de logs, et Kibana pour construire des graphiques et requêter et visualiser n’importe quelles données. L'ensemble étant assez complet, je vous oriente vers cet article du site web Wooster pour plus de détail : Introduction à ELK
Je suis loin d'avoir fait le tour des outils qui vous permettront de mettre en place la centralisation des logs dans vos parcs informatiques, mais il y en a un très grand nombre, que ce soit pour la centralisation en elle-même, pour l'indexation, le stockage ou le traitement (sécurité, graphique...). Il s'agit là d'un élément central de la sécurité d'un système d'information qui doit être pensé dès qu'il se met à grandir.









Merci pour cette article. C’est un sujet auquel je m’intéresse et que je vais lire avec attention.
merci énormément pour c sujet , j’ai bcp appris vraiment merci… si possible mm de créer aussi un truc du genre l forum
Bonsoir, sujet très vaste et vital pour avoir une visibilité sur son infrastructure.
Comment faire pour utiliser des outils Open Source dans devoir réinventer la roue…
ELK est une usine gaz et c’est casse bonbon à maintenir.
Je conseille plutôt : Loki, promtail et Grafana.
Tout dépend des besoins, si le besoin c’est juste un « grep » oui en effet.
Merci beaucoup pour cet article, c’est au programme du BTS SIO, une partie qui n’est pas simple à aborder, mais que j’appréhende mieux maintenant 🙂
Article très pertinent. Merci à vous pour votre clarté