

Dmidecode, le référentiel du BIOS et du matériel sous Linux
Sommaire
I. Présentation
Pour faire suite à l’article concernant l’affichage de la version du système sous CentOS, en poursuivant l’inventaire des informations disponibles sur un système tel que GNU/Linux, je vais aujourd’hui vous présenter un outil un peu (trop souvent) oublié: dmidecode. Cette commande possède de nombreuses options permettant d’avoir une bonne idée de ce dont la machine dispose en termes de matériels (y compris, le constructeur, le numéro de série et bien d’autres choses).
II. Le tour d’horizon du matériel
Par défaut, lorsqu’on exécute dmidecode sans paramètre, on récupère la liste intégrale de ce qui existe en tant que matériel sur l’ordinateur:
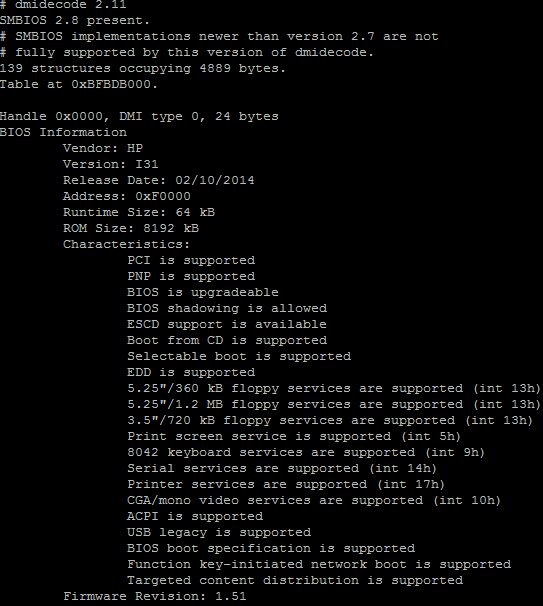
Le résultat affiché peut être très long. Il est donc conseillé de rediriger cela vers un fichier en sortie :
# dmidecode > /tmp/srvxxx_dmidecode.txt
REMARQUE : la commande est lancée en tant que root. En effet, celle-ci a besoin d’accéder au matériel via le SMBIOS (comme on peut le constater d’après la capture ci-dessus).
On peut limiter un peu la longueur des informations affichées en exécutant la commande dmidecode avec l’option –q (pour quiet). Si l’on effectue une comparaison entre les deux modes de commande, on découvre le résultat suivant :
# dmidecode|wc –l 1289 # dmidecode –q|wc –l 660
Il y a une différence de près de la moitié des lignes affichées dans le second cas. Cette différence s’explique par le fait que, par défaut, on manipule des entrées inactives et des métadonnées.
III. Les types de données
L’ensemble du matériel d’une machine est catégorisé en type numérotés. On distingue neuf classes principales :
- bios
- system
- baseboard
- chassis
- processor
- memory
- cache
- connector
- slot
Il est alors facile de lister uniquement une catégorie d’information en utilisant l’option –t :
# dmidecode –t bios
Le résultat ne listera alors que ce qui correspond à cette classe de matériel. En l’occurrence, cela correspond à la capture effectuée précédemment. En effet, la commande dmidecode affiche systématiquement les informations dans l’ordre des catégories mentionnées ci-dessus. Donc, la classe bios apparaît en premier.
On remarquera bien sûr, la classe memory permettant d’afficher l’ensemble des slots mémoire (occupés et non occupés). Si l’on souhaite disposer d’un affichage plus quantifiable voici une commande permettant de le faire :
# dmidecode –t 17|grep Size|awk '{{t+=$2}} END {{t=t/1024}print t" GB "}'
Les différentes classes identifiables par leur étiquette le sont également par un identifiant. Ainsi, la classe ‘memory’ est identifiée par la valeur 17 :
![]()
REMARQUE : on peut noter qu’il est également possible via l’option –d de lister la mémoire disponible via un fichier spécial (par défaut /dev/mem).
IV. Les classes DMI
Maintenant, si l’on souhaite véritablement afficher une information particulière, parmi toutes celles présentes dans l’affichage principal de dmidecode, on peut utiliser l’une des chaînes DMI, identifiables par leur valeur numérique (comme on l’a vu dans le chapitre précédent où les périphériques mémoire possèdent la valeur 17), au travers de l’option –s.
REMARQUE : sans autres paramètres que l’option –s, cela permet de lister l’ensemble des choix que l’on peut faire afficher :
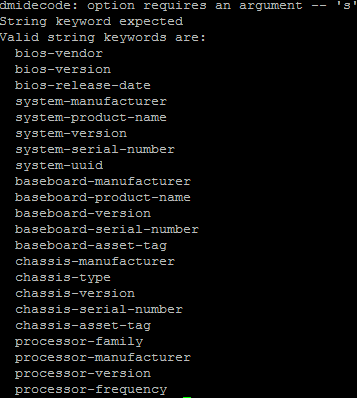
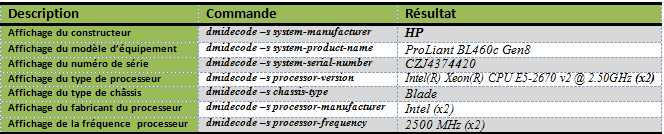
Grâce à ces indications, on peut ainsi faire afficher le constructeur de la machine, son BIOS, la version de son firmware…etc. Parmi les nombreuses possibilités, voici quelques commandes permettant de fournir de précieuses indications quant au matériel sous-jacent et, pourquoi pas de créer un script d’audit pour la qualification de l’équipement en question:
V. Dump des périphériques
Par ailleurs, il existe une option permettant de ne pas décoder les entrées de périphériques :
# dmidecode --dump
On peut également effectuer un dump mémoire (au format binaire) de l’état matériel de la machine en vue de sauvegarder celui-ci:
# dmidecode --dump-bin <Fichier>
L’opération inverse permet également de lire les informations depuis un fichier binaire :
# dmidecode –from-dump <Fichier>
VI. Conclusion
Ainsi, il est facile d’imaginer ce que l’on peut faire de ces informations, complétant celles de la version du système, vues dans un billet précédent, ainsi que celle du noyau linux utilisé. On peut se créer un script permettant de qualifier chaque machine ou poste de travail sous GNU/Linux. D'autant que cela peut alimenter une base référentielle de supervision.









