

Trier les lignes en double avec la commande uniq sous Linux
Sommaire
I. Présentation de la commande uniq
Il y a quelques jours je vous présentais la commande "sort" qui permet d'effectuer des tris sur des entrées en ligne de commande Linux. Aujourd'hui je vais vous présenter une commande tout aussi utile qui permet de trier, d'afficher ou d'omettre dans l'affichage les lignes en doublons (ou plus). Certains contextes de travail (script ou gestion des logs par exemple) requièrent d'exclure ou de faire sortir les doublons lors d'une commande.
II. Cas d'utilisation de la commande uniq sous Linux
Durant ce tutoriel, je vais travailler avec le fichier "file.txt" ayant le contenu suivant :
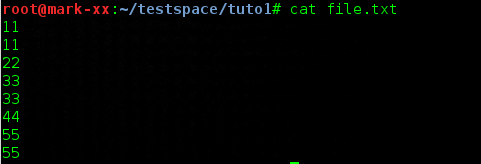
Cela vous permettra de mieux vous repérer dans l'exposition des options de la commande et de comprendre ce dont vous pouvez avoir besoin 🙂 .
A. Exclure les doublons
L'utilisation "standard" de uniq, c'est à dire sans option, affiche le contenu qu'on lui donne en excluant les lignes en double afin de n'avoir qu'une seule occurrence de celles-ci :
uniq file.txt
Résultat :
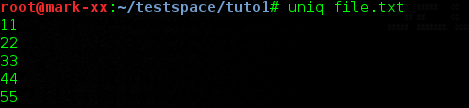
B. N'afficher que les lignes présentes une fois
Il est également possible de ne faire ressortir que les lignes présentes une seule fois dans notre fichier, les lignes présentes plusieurs fois seront alors totalement exclues de l'affichage :
uniq file.txt -u
Résultat :

C. N'afficher que les lignes présentes plusieurs fois
A l'inverse, il est également possible de n'afficher que les lignes présentes plusieurs fois dans le fichier donné, celles-ci seront affichées une seule fois dans la sortie :
uniq file.txt -d
Résultat :

Il est également possible d'effectuer le même traitement mais cette fois ci en affichant toutes les occurrences des lignes présentes plusieurs fois, on utilisera pour cela l'option "-D":
uniq file.txt -D
Résultat :
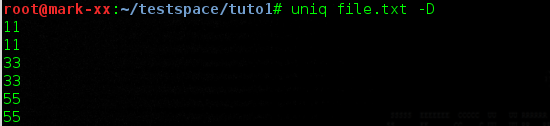
D. Compter les occurrences des lignes en double
Une autre option très pratique est celle permettant de compter le nombre d'occurrence par ligne avec l'option "-c" :
uniq file.txt -c
Résultat :
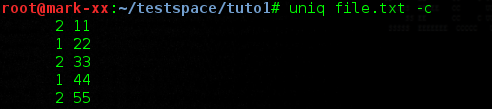 On voit ici que la ligne "11" est présente deux fois, alors que la ligne "22" n'est elle présente qu'une fois. Une petite astuce, on peut utiliser la commande "sort" pour effectuer un tri croissant de cette sortie :
On voit ici que la ligne "11" est présente deux fois, alors que la ligne "22" n'est elle présente qu'une fois. Une petite astuce, on peut utiliser la commande "sort" pour effectuer un tri croissant de cette sortie :
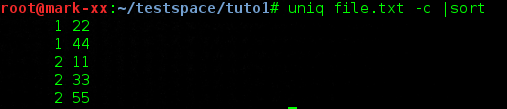
uniq file.txt -c |sort
Résultat :
J'ai par exemple déjà eu à utiliser le couple uniq + sort dans le cadre d'analyse de logs web pour faire ressortir certaines IP 😉 J'espère que ce tutoriel vous aura été utile et que vous retiendrez la commande "uniq" qui est bien pratique !









Bonjour,
Je constate que la commande uniq ne permet de supprimer QUE les doublons CONSÉCUTIFS.
Si par exemple le fichier file.txt contient
11
12
12
13
11
12
Et que l’on lance la commande uniq file.txt -c, cela donnera:
1 11
2 12
1 13
1 11
1 12
Ce qui ne correspond pas à la réalité des doublons du fichier file.txt !
La solution que je vois est de faire un classement alphabétique lors de la création du fichier file.txt (avec un sort):
cat file.txt |sort | uniq -c
2 11
3 12
1 13
->sort file.txt | uniq -c suffit