

Gestion des ressources et optimisation des performances
L’un des défis majeurs de la conteneurisation réside dans la maîtrise des ressources. Un conteneur peut consommer excessivement le processeur, la mémoire ou le stockage, ce qui dégrade l’ensemble du système. À grande échelle, notamment en environnement de production, il devient crucial de garantir une répartition équitable et une utilisation optimale des ressources disponibles.
Ce chapitre aborde les principes fondamentaux et les bonnes pratiques de gestion des ressources dans Docker et Kubernetes, en insistant sur leur application concrète dans un environnement Linux moderne
Sommaire
Comprendre la gestion des ressources dans Docker
Avant d’imposer des limites, il est essentiel de comprendre comment Docker interagit avec les ressources du système hôte.
Docker repose sur les cgroups (control groups) du noyau Linux pour contrôler la quantité de CPU, de mémoire, de disque ou de réseau qu’un conteneur peut utiliser. Les cgroups permettent d’isoler et de restreindre les ressources disponibles pour chaque processus ou groupe de processus, ce qui évite qu’un conteneur accapare toutes les ressources de la machine.
Docker utilise également les namespaces, qui isolent les processus, les utilisateurs, le réseau et les systèmes de fichiers entre conteneurs. Ensemble, les cgroups et namespaces assurent l’isolation, mais seuls les cgroups gèrent quantitativement la consommation.
Limitation des ressources CPU et mémoire
Pourquoi limiter les ressources ?
Limiter les ressources d’un conteneur permet :
- D’éviter qu’un service monopolise le processeur au détriment des autres
- De prévenir une surconsommation mémoire entraînant un Out Of Memory (OOM)
- D’améliorer la prévisibilité des performances
- De renforcer la stabilité du système dans son ensemble
Sans limitation, Docker laisse chaque conteneur accéder à toutes les ressources disponibles, ce qui est acceptable pour les tests, mais dangereux en production.
Limiter l’usage CPU
Docker permet de définir combien de temps CPU un conteneur peut consommer par rapport à l’hôte.
Nous allons ici créer un conteneur de test isolé, sans interférer avec ceux du cluster Kubernetes. Pour cela, on utilise l’image progrium/stress, qui permet de simuler une charge CPU :
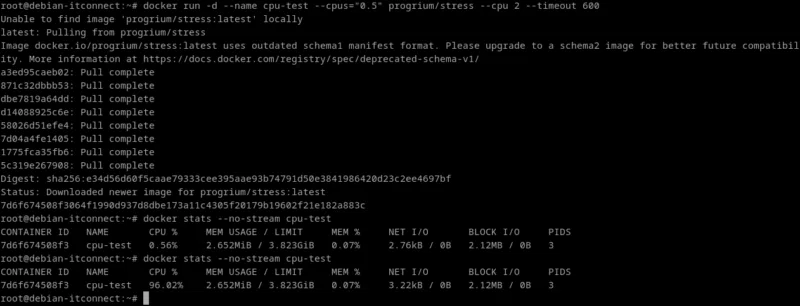
docker run -d --name cpu-test --cpus="0.5" progrium/stress --cpu 2 --timeout 600Explications :
--cpus="0.5": le conteneur ne pourra pas dépasser 0,5 processeur logique.--cpu 2: on crée deux processus consommateurs de CPU pour observer la limite.--timeout 600: le test dure 10 minutes.
Observons :
docker stats --no-stream cpu-testLa colonne CPU % montre que la consommation reste inférieure à ce que 0,5 CPU permet. Cette commande fournit aussi la mémoire utilisée, les I/O et le trafic réseau en temps réel.
Une grande force de Docker est la possibilité de modifier les limites sans redémarrer le conteneur :
docker update --cpus="1.5" cpu-testLa commande précédente accorde au conteneur jusqu’à 1,5 CPU. Une nouvelle vérification avec docker stats permet d’observer l’évolution.
Vous pouvez envisager un contrôle plus fin avec --cpu-quota et --cpu-period. Ces deux paramètres définissent le quota de temps CPU autorisé dans une période de contrôle.
Par défaut, la période (--cpu-period) vaut 100 000 microsecondes (soit 100 ms). Le quota (--cpu-quota) correspond à la portion de cette période pendant laquelle le conteneur peut exécuter des instructions CPU.
Ainsi, pour accorder 1,5 CPU :
docker update --cpu-period=100000 --cpu-quota=150000 cpu-testCela signifie que le conteneur pourra exécuter du code 150 000 µs sur chaque tranche de 100 000 µs (soit 1,5 fois la puissance d’un CPU logique).
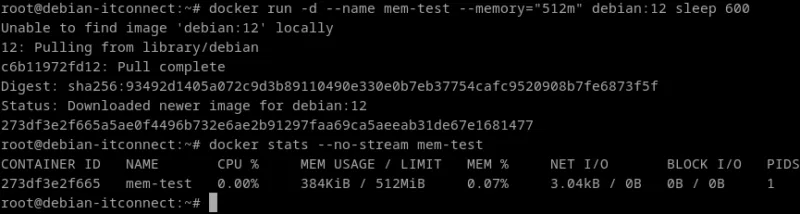
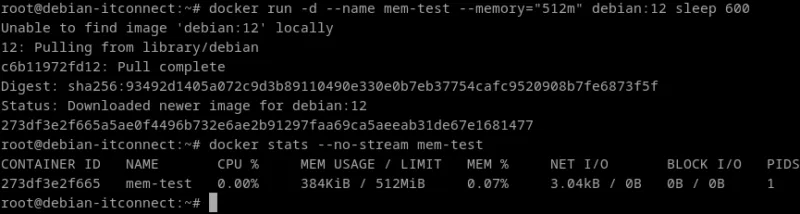
Limiter la mémoire
La mémoire vive est tout aussi critique que le CPU. Une application mal codée peut provoquer un débordement (Out of Memory) et tuer d’autres conteneurs.
Par exemple :
docker run -d --name mem-test --memory="512m" debian:12 sleep 600Ce conteneur ne pourra pas dépasser 512 Mo de RAM.
S’il tente d’allouer davantage, le OOM Killer (mécanisme du noyau) mettra fin à son exécution.
On peut ajouter du swap :
--memory="512m" --memory-swap="1g"Cela autorise 512 Mo en RAM physique et jusqu’à 1 Go en incluant la mémoire d’échange (swap).
Pour améliorer les performances et éviter les interférences, Docker peut forcer un conteneur à s’exécuter sur un cœur particulier :
docker update --cpuset-cpus="0-1" cpu-testLe conteneur sera confiné aux cœurs 0 et 1, pratique pour isoler un service critique.
Une fois les tests terminés, nous pouvons nettoyer :
docker rm -f cpu-test mem-test
Stratégies d’optimisation pour la production
Une bonne configuration des ressources est indissociable d’une surveillance constante. Optimiser les performances revient à observer, mesurer, ajuster et itérer.
Outils de surveillance
Sur notre machine, plusieurs outils sont déjà disponibles :
docker statspour une vue rapide des conteneurs locaux- cAdvisor, développé par Google, pour une analyse plus poussée
- Prometheus + Grafana pour une surveillance centralisée et graphique
Ces outils permettent de détecter précocement les surcharges et d’anticiper les besoins en scalabilité.
Alléger les images Docker
La taille des images influe directement sur les performances, surtout lors des déploiements automatisés.
Quelques règles simples :
- Utiliser des images minimalistes :
alpine,debian:bookworm-slim, etc… - Nettoyer les caches dans les Dockerfiles :
RUN apt-get update && apt-get install -y nginx && rm -rf /var/lib/apt/lists/* - Utiliser les multi-stage builds pour séparer la compilation et l’exécution.
Une image légère démarre plus vite, consomme moins de réseau et nécessite moins de stockage.
Gérer les logs pour éviter la saturation disque
Docker stocke les journaux des conteneurs dans /var/lib/docker/containers/. Une mauvaise gestion de ces fichiers peut saturer le disque.
Une politique de rotation peut être définie dans /etc/docker/daemon.json, comme nous l’avons déjà vu dans un précédent chapitre.
Utilisation de Docker et Kubernetes pour optimiser la scalabilité et la résilience
La conteneurisation ne se limite pas à isoler et contrôler les ressources : elle ouvre la voie à une infrastructure hautement scalable et résiliente.
Docker et Kubernetes, lorsqu’ils sont utilisés conjointement, permettent d’atteindre un niveau d’élasticité et de tolérance aux pannes qu’il serait difficile d’obtenir avec des machines virtuelles classiques.
La notion de scalabilité dans un environnement conteneurisé
Scalabilité signifie la capacité d’un système à s’adapter à la charge :
- En ajoutant ou retirant des ressources (scalabilité horizontale)
- Ou en renforçant la puissance des ressources existantes (scalabilité verticale)
Les conteneurs simplifient considérablement cette démarche :
- Ils démarrent en quelques secondes
- Ils consomment peu de ressources système au repos
- Ils peuvent être répliqués et détruits à la volée sans impact sur le noyau hôte.
Grâce à Docker, il devient possible d’orchestrer facilement plusieurs instances d’un même service.
Avec Kubernetes, cette orchestration devient automatique et intelligente.
Scalabilité horizontale avec Docker
Même sans Kubernetes, Docker peut déjà assurer un certain niveau de scalabilité via Docker Compose ou Docker Swarm.
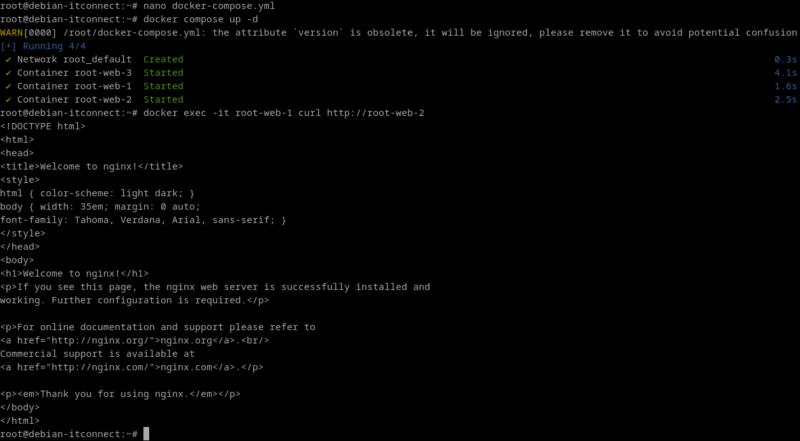
Un simple fichier docker-compose.yml peut déployer plusieurs instances d’un service. Voici un exemple concret.
version: '3.9'
services:
web:
image: nginx
deploy:
replicas: 3
resources:
limits:
cpus: '0.5'
memory: 512MUne fois lancé avec :
docker compose up -dDocker déploie 3 conteneurs identiques (réplicas) partageant la même configuration. Si l’un d’eux tombe, il peut être recréé manuellement, ou automatiquement dans un environnement Swarm.
Cette méthode permet de simuler un mini-balayage horizontal sur une seule machine.
Docker Swarm : introduction à l’orchestration native
Docker Swarm est l’orchestrateur intégré à Docker. Il permet :
- La distribution des conteneurs sur plusieurs hôtes (nœuds du cluster)
- La gestion automatique du placement et de la réplication
- Le basculement automatique en cas de panne
Sur notre machine, il serait possible d’initialiser un cluster Swarm ainsi :
docker swarm init --advertise-addr 192.168.1.21Remarques :
--advertise-addrindique l’adresse que les autres nœuds utiliseront pour joindre le manager- Par défaut, Docker écoute sur
0.0.0.0:2377pour le contrôle Swarm. Si besoin d’être explicite :docker swarm init --advertise-addr 192.168.1.21 --listen-addr 0.0.0.0:2377
Puis de déployer un service répliqué :
docker service create --name web --replicas 3 nginx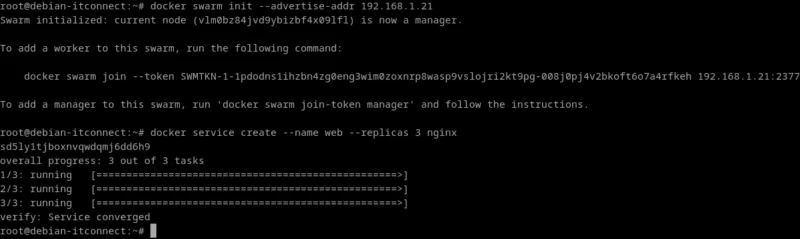
Le service est maintenant hautement disponible : si un conteneur échoue, Swarm en relance un autre automatiquement. Bien que Kubernetes soit plus complet, Swarm illustre la philosophie Docker : des déploiements rapides, résilients et légers.
Scalabilité et résilience avancées avec Kubernetes
Kubernetes étend le principe de Docker Swarm à une échelle bien plus vaste. Il ne se contente pas de répliquer : il observe, planifie et réagit à la charge et aux défaillances.
Scalabilité horizontale automatique
Grâce au Horizontal Pod Autoscaler (HPA), Kubernetes ajuste le nombre de Pods selon la charge CPU (ou d’autres métriques).
Sur notre machine, nous avons déjà activé le metrics-server. La commande suivante crée un HPA sur le déploiement hello :
kubectl autoscale deployment hello --cpu-percent=60 --min=1 --max=5
Ce mécanisme suit la consommation CPU moyenne des Pods :
- Si elle dépasse 60 %, Kubernetes augmente le nombre de Pods
- Si elle retombe sous le seuil, Kubernetes réduit le nombre de réplicas
Ainsi, le cluster s’adapte en temps réel à la charge sans intervention humaine.
Scalabilité verticale
Kubernetes peut aussi ajuster dynamiquement les limites de ressources d’un Pod grâce au Vertical Pod Autoscaler (VPA). Cela permet d’augmenter la mémoire ou le CPU d’un Pod sans le répliquer.
Cette approche est utile pour les applications qui ne supportent pas bien la répartition de charge horizontale.
Le Load Balancing et le Service Discovery
Pour que la scalabilité horizontale soit efficace, il faut distribuer la charge entre les Pods.
Kubernetes crée automatiquement un Service qui agit comme un répartiteur de charge interne :
kubectl expose deployment hello --port=80 --target-port=80 --type=NodePort
Chaque requête adressée au Service hello est redirigée vers un Pod disponible, assurant la continuité du service même si l’un d’eux échoue.
La résilience : principe d’auto-guérison
Kubernetes surveille en permanence l’état de chaque Pod, conteneur et nœud du cluster. Lorsqu’une défaillance est détectée, il réagit de manière autonome :
- Si un Pod plante, le contrôleur ReplicaSet le redémarre automatiquement
- Si un nœud devient injoignable, les Pods qu’il héberge sont redéployés ailleurs
- Les sondes
livenessProbeetreadinessProbepermettent de détecter les applications figées et de relancer uniquement celles défaillantes.
Examinons un exemple concret :
livenessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 5
timeoutSeconds: 3
failureThreshold: 2Ce type de configuration rend les applications auto-réparables. Elles reviennent à l’état de fonctionnement sans aucune intervention humaine.
En maîtrisant l'allocation précise des ressources et les mécanismes d'auto-scaling, vous êtes désormais capable de garantir la stabilité et la performance de vos applications face aux variations de charge. Ces compétences constituent le socle d'une infrastructure résiliente, où Kubernetes assure la continuité de service de manière autonome et efficace.







