

Orchestration des conteneurs avec Kubernetes
Après avoir maîtrisé la création de conteneurs individuels, il est temps de découvrir comment orchestrer des architectures résilientes à grande échelle. Ce chapitre vous guidera à travers les concepts fondamentaux de Kubernetes avant de vous accompagner, pas à pas, dans l'installation et la prise en main de votre propre cluster local avec Minikube.
Sommaire
Kubernetes pour la gestion de conteneurs à grande échelle
L’apparition des conteneurs a profondément changé la manière dont les applications sont conçues, testées et déployées. Là où les environnements traditionnels nécessitaient souvent des configurations lourdes, instables et spécifiques à chaque machine, la conteneurisation a apporté une approche radicalement différente : celle de l’isolation, de la portabilité et de la reproductibilité. Grâce à des technologies comme Docker, il est devenu possible d’encapsuler une application et toutes ses dépendances dans une unité légère, appelée conteneur, capable de s’exécuter de manière identique sur n’importe quel environnement compatible.
Cependant, si gérer une poignée de conteneurs est encore à la portée d’un administrateur ou d’un développeur, le passage à l’échelle, c’est-à-dire le déploiement de centaines voire de milliers de conteneurs, pose de nouveaux défis. Comment s’assurer que chaque conteneur s’exécute sur la machine la plus adaptée ? Comment répartir la charge de manière équitable entre les instances ? Comment relancer automatiquement un conteneur en cas de panne ou de mise à jour ? Et surtout, comment garantir que l’ensemble du système reste cohérent, stable et sécurisé dans le temps ?
C’est précisément pour répondre à ces problématiques qu’est né Kubernetes, souvent abrégé K8s.
Kubernetes a été développé à l’origine par Google, qui cherchait à rendre publique une partie de l’expérience acquise avec ses propres systèmes internes d’orchestration (notamment Borg et Omega). L’entreprise maîtrisait déjà depuis longtemps l’exécution de milliers de services conteneurisés sur une infrastructure mondiale. En 2014, Google a donc publié Kubernetes en open source, sous l’égide de la Cloud Native Computing Foundation (CNCF). Depuis, ce projet est devenu un standard de fait dans le monde du cloud et du DevOps.
Kubernetes se définit comme un système d’orchestration de conteneurs. Son rôle est d’automatiser tout le cycle de vie des conteneurs : le déploiement, la mise à l’échelle, la surveillance, le redémarrage en cas d’échec, et même la mise à jour continue. Il agit comme un chef d’orchestre, qui coordonne chaque instrument (les conteneurs) afin que l’ensemble joue en harmonie, selon une partition prédéfinie (la configuration du cluster).
Le principe de base de Kubernetes repose sur une idée puissante : vous ne dites pas au système comment faire, mais ce que vous voulez obtenir. C’est ce qu’on appelle un modèle déclaratif.
Par exemple, plutôt que de lancer manuellement trois conteneurs NGINX, vous déclarez dans un fichier YAML : « Je veux trois instances de cette application web ». Kubernetes se charge alors d’assurer que trois conteneurs soient toujours en cours d’exécution, en relançant ceux qui tombent en panne et en répartissant la charge entre eux.
Cette approche change profondément la philosophie de l’administration système. On ne “pilote” plus chaque composant un par un ; on décrit un état cible, et Kubernetes veille en permanence à ce que cet état soit respecté.
L’architecture de Kubernetes est conçue pour fonctionner dans des environnements très variés : elle peut être déployée sur un simple ordinateur portable pour le développement, sur un cluster de serveurs dans un data center, ou encore sur les grandes plateformes cloud publiques comme AWS, Azure ou Google Cloud. Dans tous les cas, le fonctionnement reste identique : une couche de contrôle (control plane) pilote un ensemble de nœuds (nodes), chacun hébergeant un ou plusieurs conteneurs.
En production, Kubernetes permet d’obtenir :
- Une résilience élevée, grâce à la redondance automatique des composants.
- Une mise à l’échelle dynamique, capable d’ajouter ou de retirer des instances en fonction de la charge.
- Une portabilité absolue, puisque les mêmes fichiers de configuration peuvent être déployés sur différents environnements.
- Et surtout, une automatisation poussée, réduisant drastiquement les interventions manuelles et les erreurs humaines.
Kubernetes n’est pas seulement un outil d’administration de conteneurs, c’est un véritable système d’exploitation pour le cloud. Il permet aux entreprises d’exécuter leurs applications comme s’il s’agissait d’un seul grand ordinateur, composé de centaines de machines physiques ou virtuelles, mais géré de manière unifiée et automatisée.
Concepts de base : pods, déploiements, services, et auto-scaling
Pour comprendre le fonctionnement de Kubernetes, il est essentiel d’en connaître les concepts fondamentaux. Ces briques de base constituent le langage commun à travers lequel on décrit, déploie et supervise des applications conteneurisées dans un cluster.
Les Pods
Le Pod est l’unité la plus petite et la plus fondamentale dans Kubernetes. Il ne s’agit pas simplement d’un conteneur, mais d'une enveloppe logique autour d’un ou plusieurs conteneurs étroitement liés. Ces conteneurs partagent le même réseau, le même stockage, et communiquent entre eux comme s’ils étaient sur la même machine.
En pratique, un Pod contient souvent un seul conteneur, mais il peut en héberger plusieurs dans des cas spécifiques, par exemple lorsqu’un conteneur principal a besoin d’un conteneur “assistant”, comme un proxy ou un collecteur de logs.
Les Pods sont éphémères : ils peuvent être créés, détruits et recréés à tout moment. Si un Pod tombe, Kubernetes s’assure d’en créer un nouveau ailleurs dans le cluster. Cette nature transitoire est essentielle : elle garantit la résilience du système, mais impose aussi de ne jamais stocker de données critiques à l’intérieur même des Pods (on utilise plutôt des volumes persistants).
Un Pod se décrit au moyen d’un fichier YAML, par exemple :
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80Les Déploiements (Deployments)
Gérer un seul Pod manuellement n’est pas viable à grande échelle. C’est pourquoi Kubernetes propose le concept de Deployment. Un Deployment est un contrôleur : il définit combien de copies d’un Pod doivent exister, veille à ce que ce nombre soit respecté et gère les mises à jour progressives.
Lorsqu’un Deployment est appliqué, Kubernetes crée en arrière-plan un autre objet appelé ReplicaSet, chargé de maintenir le nombre exact de Pods souhaités. Si un Pod est supprimé ou échoue, le ReplicaSet en crée un nouveau.
Cette abstraction simplifie énormément la vie des administrateurs et des développeurs. Par exemple, pour déployer une application web en trois exemplaires, il suffit de déclarer un Deployment :
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.25
ports:
- containerPort: 80Ce Deployment indique à Kubernetes qu’il doit exécuter trois Pods identiques, chacun contenant un conteneur NGINX. Si l’un d’eux tombe, un nouveau sera automatiquement créé.
Lorsqu’une nouvelle version de l’application est disponible, on peut simplement mettre à jour l’image Docker dans le fichier YAML ; Kubernetes effectuera un rolling update : il remplacera les Pods un à un, sans jamais interrompre le service.
Cette capacité à effectuer des déploiements sans interruption et à revenir en arrière en cas d’échec est l’un des atouts majeurs de Kubernetes.
Les Services
Les Pods sont volatils : leurs adresses IP changent constamment. Pour rendre une application accessible de manière stable, Kubernetes introduit la notion de Service.
Un Service agit comme un point d’entrée stable vers un ensemble de Pods. Il possède sa propre adresse IP fixe et distribue le trafic réseau entre les Pods qu’il cible, jouant ainsi le rôle d’un load balancer interne.
Les Services peuvent être de différents types :
- ClusterIP : accessible uniquement à l’intérieur du cluster (usage interne).
- NodePort : expose le service sur un port du nœud hôte (utile pour les tests ou les environnements simples).
- LoadBalancer : crée un point d’accès externe, souvent couplé à un load balancer cloud.
Voici un exemple simple :
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
selector:
app: nginx
ports:
- port: 80
targetPort: 80
type: LoadBalancerCe Service redirige tout le trafic entrant sur le port 80 vers les Pods dont le label app: nginx est défini.
Grâce à ce mécanisme, les applications deviennent accessibles aussi bien depuis l’extérieur du cluster que depuis d’autres services internes, sans se soucier de l’adresse IP réelle des Pods.
L’auto-scaling
L’un des aspects les plus puissants de Kubernetes est sa capacité à adapter automatiquement les ressources en fonction de la charge.
L’auto-scaling se décline à plusieurs niveaux, mais le plus connu est le Horizontal Pod Autoscaler (HPA). Le HPA surveille en continu les métriques (comme l’utilisation CPU ou mémoire) et ajuste dynamiquement le nombre de Pods pour maintenir la performance tout en optimisant les ressources.
Par exemple :
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: nginx-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx-deployment
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60Dans cet exemple, Kubernetes veille à ce que l’utilisation moyenne du CPU reste autour de 60 %. Si la charge augmente, il crée automatiquement de nouveaux Pods ; si elle diminue, il en supprime.
Ce mécanisme rend le système hautement élastique, capable de réagir instantanément à la demande sans intervention humaine.
Nous reviendrons ultérieurement en détail sur tous ces composants fondamentaux.
Installation d’un cluster Kubernetes
Mettre en place un cluster Kubernetes peut paraître complexe au premier abord, mais le principe général reste le même : il s’agit de disposer d’un plan de contrôle (control plane) et de nœuds de travail (worker nodes). Le plan de contrôle orchestre l’ensemble, tandis que les nœuds hébergent les Pods réels.
Choix des solutions d’installation
Il existe plusieurs manières d’installer Kubernetes, selon l’usage et la taille de l’environnement :
- Minikube : parfait pour l’apprentissage et les tests locaux. Il crée un cluster à nœud unique sur votre machine.
- Kind (Kubernetes IN Docker) : déploie un cluster Kubernetes dans des conteneurs Docker, idéal pour la CI/CD.
- kubeadm : l’outil officiel pour créer un cluster complet, généralement sur plusieurs serveurs.
- Solutions managées : GKE (Google), AKS (Azure), EKS (AWS), OVH Managed K8s… Ces services gèrent l’infrastructure et les mises à jour à votre place.
Pour expérimenter Kubernetes sans infrastructure complexe, Minikube est la solution la plus simple. Nous allons présenter son installation.
Installer et configurer kubectl sur Linux
Prérequis importants
Avant d’installer kubectl, il faut garder en tête une règle de compatibilité très simple mais essentielle. Le client kubectl doit être à une version mineure près de la version du cluster Kubernetes auquel vous allez vous connecter. Concrètement, un client en v1.x fonctionne avec un serveur en v1.x-1, v1.x ou v1.x+1. Utiliser la dernière version stable de kubectl réduit le risque de comportements inattendus.
Au cours de cette présentation, nous supposons être authentifiés en tant que root.
Méthode n°1 - Installer le binaire kubectl avec curl sur Linux
Cette méthode consiste à télécharger directement le binaire pré-compilé, à lui donner les droits d’exécution, puis à le placer dans un répertoire présent dans votre PATH système. C’est rapide et indépendant de la distribution.
Téléchargeons la dernière version stable du binaire pour Linux amd64. La commande ci-dessous récupère d’abord le numéro de version stable, puis télécharge le binaire correspondant.
curl -LO https://dl.k8s.io/release/$(curl -Ls https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectlSi nous souhaitons une version précise, remplacez la sous-commande qui lit stable.txt par le tag voulu, par exemple v1.34.0 :
curl -LO https://dl.k8s.io/release/v1.34.0/bin/linux/amd64/kubectlRendons le binaire exécutable.
chmod +x ./kubectlDéplaçons le binaire dans un répertoire inclus dans notre PATH, généralement /usr/local/bin.
mv ./kubectl /usr/local/bin/kubectlVérifions la version du client pour confirmer l’installation.
kubectl version -client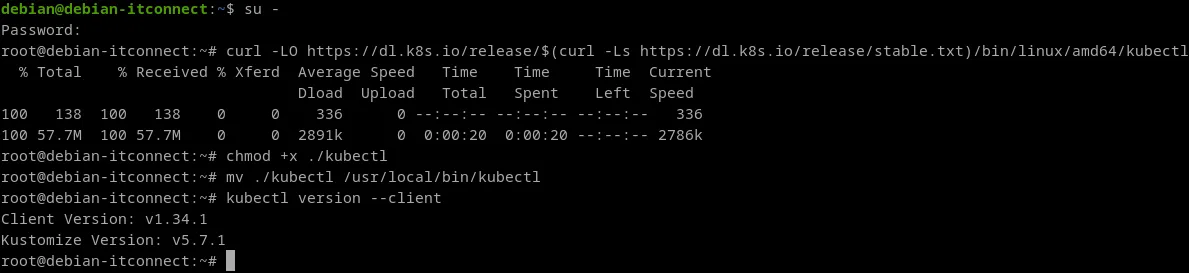
Méthode n°2 - Installer via les gestionnaires de paquets natifs
Cette approche est conseillée si vous préférez l’intégration avec votre gestionnaire de paquets, la réception des mises à jour et la gestion standardisée des clés GPG. Nous allons présenter les étapes théoriques via cette méthode pour Debian.
Commencez par préparer le système, créer l’anneau de clés, ajouter la clé de signature du dépôt pkgs.k8s.io pour la branche stable et déclarer la source APT. Ensuite, mettez à jour l’index et installez kubectl. Les étapes sont à réaliser en tant que root ou via sudo.
apt-get update && apt-get install -y apt-transport-https ca-certificates curl gnupg
mkdir -p -m 755 /etc/apt/keyrings
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.33/deb/Release.key | gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
chmod 644 /etc/apt/keyrings/kubernetes-apt-keyring.gpg
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.33/deb/ /' | tee /etc/apt/sources.list.d/kubernetes.list
chmod 644 /etc/apt/sources.list.d/kubernetes.list
apt-get update
apt-get install -y kubectlActivation de l’auto-complétion du shell
L’une des fonctionnalités les plus pratiques de kubectl, et souvent sous-estimée, est son système d’auto-complétion.
Celui-ci permet de gagner un temps considérable lors de l’utilisation quotidienne de l’outil, en proposant automatiquement les sous-commandes, les options ou les noms de ressources dès que vous commencez à les taper.
Par exemple, si vous saisissez kubectl g puis appuyez sur la touche Tab, le shell complétera automatiquement en kubectl get, ou vous proposera les sous-commandes possibles si plusieurs choix existent.
Ce mécanisme repose sur un script de complétion qui interagit directement avec le shell. Cependant, il faut effectuer quelques étapes de configuration pour que cette fonctionnalité soit active dans toutes vos sessions.
Note : Kubernetes fournit par défaut un script de complétion pour Bash et Zsh, deux des environnements les plus utilisés par les administrateurs système.
Le script de complétion Bash de kubectl peut être généré grâce à la commande suivante :
kubectl completion bashCette commande produit un long script qui contient la logique nécessaire pour proposer dynamiquement des suggestions de complétion en fonction des sous-commandes et des options disponibles dans kubectl.
Ce script ne modifie pas votre système : il ne fait que définir des fonctions Bash utilisées par la complétion.
Pour que la complétion soit effective, il faut que ce script soit sourcé dans votre shell, c’est-à-dire chargé dans votre environnement Bash actif.
Vous pouvez soit le charger manuellement, soit l’ajouter à votre fichier de configuration ~/.bashrc pour qu’il soit automatiquement exécuté à chaque ouverture de terminal.
Avant d’aller plus loin, il faut savoir que ce script dépend d’un autre composant essentiel : bash-completion.
Ce paquet, disponible sur la plupart des distributions Linux, met à disposition l’infrastructure nécessaire à la complétion intelligente dans Bash. Sans lui, le script de kubectl ne pourra pas fonctionner correctement. Nous supposons que ce composant est déjà installé sur votre système.
Une fois bash-completion correctement installé et fonctionnel, il faut maintenant dire à votre shell de charger le script de complétion de kubectl.
Pour ce faire, il suffit d’ajouter la ligne suivante à la fin de votre fichier ~/.bashrc :
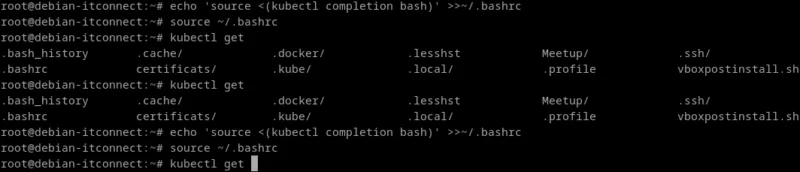
echo 'source <(kubectl completion bash)' >>~/.bashrcCette commande ajoute une ligne qui exécutera automatiquement le script de complétion de kubectl chaque fois que nous ouvrirons un terminal. Ainsi, l’auto-complétion sera disponible immédiatement après le chargement de votre shell.
Rechargeons votre environnement pour tester :
source ~/.bashrcPuis essayons :
kubectl g<Tab>Vous devriez voir apparaître la complétion de la commande avec kubectl get.
Installation de Minikube à l’aide d’un package
Minikube est un outil qui permet d’exécuter un cluster Kubernetes local sur votre ordinateur, dans une machine virtuelle ou un conteneur. C’est la solution idéale pour tester Kubernetes, expérimenter ses fonctionnalités et apprendre à le manipuler sans devoir déployer une infrastructure complète.
Par défaut, Minikube s’appuie sur une machine virtuelle (VM), gérée par un hyperviseur comme VirtualBox, QEMU, KVM ou VMware. Cependant, il existe une autre option particulièrement intéressante : le mode --vm-driver=none.
Ce mode exécute directement tous les composants Kubernetes sur la machine hôte plutôt que dans une machine virtuelle. Autrement dit, le cluster tourne directement sur votre système Linux, sans couche de virtualisation intermédiaire.
Ce mode présente plusieurs avantages :
- Il permet de gagner en performance puisque tout s’exécute nativement sur la machine.
- Il ne nécessite aucun hyperviseur, seulement Docker et un système Linux fonctionnel.
Cependant, il a aussi quelques contraintes :
- Il ne fonctionne que sur Linux, car il repose sur le système hôte.
- Il nécessite d’exécuter Minikube avec des privilèges administratifs (root), puisque certains composants du cluster doivent accéder à des ports et services système.
Dans le cadre de ce cours, nous utiliserons Minikube à l’intérieur d’une machine virtuelle Linux, afin de garder un environnement bien isolé et reproductible.
Nous supposons donc que Docker est déjà installé et opérationnel sur cette VM, ce qui permettra à Minikube de l’utiliser comme moteur d’exécution pour les conteneurs.
Ainsi, sauf mention contraire, nous utiliserons le driver Docker via l’option :
minikube start --driver=dockerL’équipe Kubernetes met à disposition un package officiel permettant d’installer facilement Minikube sur la plupart des systèmes Linux.
Cette méthode est la plus simple et la plus sûre : elle installe une version stable et gérée par le projet Kubernetes lui-même.
Commençons par télécharger la dernière version du package .deb de Minikube (pour les systèmes basés sur Debian/Ubuntu) à l’aide de la commande suivante :
curl -Lo minikube https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64 && chmod +x minikubePour rendre Minikube accessible depuis n’importe quel dossier du système, déplaçons-le dans un répertoire présent dans votre variable d’environnement PATH (généralement /usr/local/bin) :
mkdir -p /usr/local/bin/
install minikube /usr/local/bin/Une fois cette étape terminée, le binaire Minikube est disponible dans notre PATH. Nous pouvons vérifier que l’installation s’est bien déroulée avec :
minikube version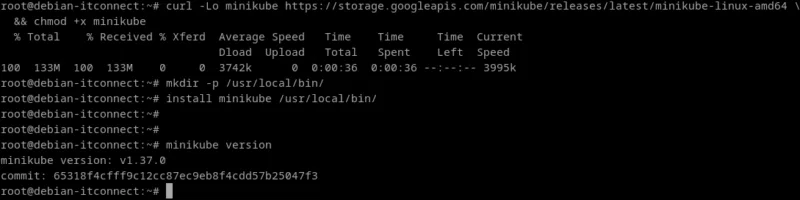
Vérifier et démarrer Minikube
Une fois Minikube installé, la première étape consiste à vérifier qu’il peut démarrer correctement un cluster Kubernetes local.
Exécutons la commande suivante pour créer et initialiser le cluster :
minikube start --driver=noneRemarque : si vous utilisez un autre hyperviseur (VirtualBox, KVM, VMware, etc.), remplacez docker par le nom du driver correspondant, toujours en minuscules :
minikube start --driver=virtualboxLa liste complète des drivers disponibles est consultable dans la documentation officielle de Minikube.
Minikube télécharge automatiquement les composants nécessaires à Kubernetes (images, outils du plan de contrôle, etc.) puis initialise le cluster local. Le processus peut durer quelques minutes lors de la première exécution.
Une fois l’installation de Minikube terminée et le cluster initialisé avec succès, il est essentiel de vérifier que l’ensemble des composants fonctionne correctement. Kubernetes est un système distribué, composé de plusieurs services et processus interdépendants. Avant de déployer la moindre application, il faut donc s’assurer que le plan de contrôle (control plane) et les composants du nœud (node components) sont bien opérationnels.
Gestion d'un cluster Kubernetes
Avant d'envisager le déploiement d'une première application, nous allons passer en revue un ensemble de commandes permettant de vérifier l'état de santé de l'installation.
Vérification du statut général du cluster
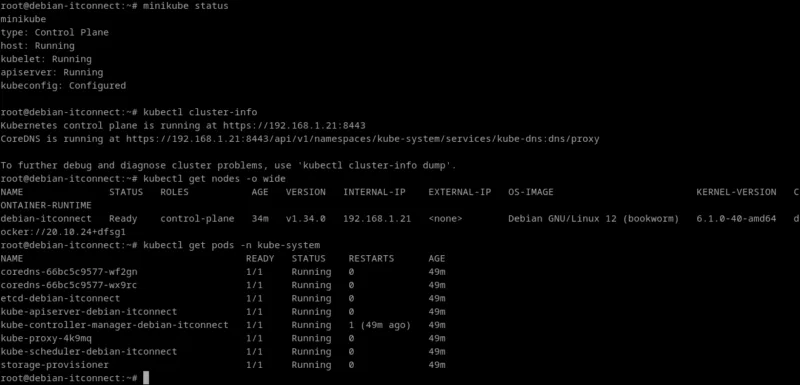
La première étape consiste à interroger Minikube afin de vérifier l’état global du cluster. La commande suivante donne une vue d’ensemble de la santé des principaux services :
minikube statusCette commande retourne généralement plusieurs lignes, chacune correspondant à un composant clé :
- host : indique l’état de la machine hôte sur laquelle Kubernetes est exécuté. Elle doit être marquée comme Running.
- kubelet : c’est l’agent principal de chaque nœud. Il doit être Running pour que les pods puissent être créés et gérés.
- apiserver : c’est le cœur du plan de contrôle. S’il est Running, cela signifie que le cluster peut accepter des commandes et orchestrer les ressources.
- kubeconfig : confirme que le fichier de configuration de kubectl est bien relié au cluster.
Une sortie typique pourrait ressembler à ceci :
root@debian-itconnect:~# minikube status
minikube
type: Control Plane
host: Running
kubelet: Running
apiserver: Running
kubeconfig: ConfiguredSi ces quatre éléments apparaissent comme Running et Configured, cela signifie que le cluster Minikube est fonctionnel et prêt à accueillir des déploiements.
Vérification de la communication entre kubectl et le cluster
Kubernetes étant piloté par l’utilitaire en ligne de commande kubectl, il est crucial de s’assurer que ce dernier est correctement configuré pour communiquer avec le serveur API du cluster. Pour cela, on peut exécuter :
kubectl cluster-infoLa commande affiche l’adresse du Kubernetes control plane, ainsi que celle du DNS Core interne. Par exemple :
root@debian-itconnect:~# kubectl cluster-info
Kubernetes control plane is running at https://192.168.1.21:8443
CoreDNS is running at
https://192.168.1.21:8443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.Si ces informations apparaissent sans erreur, cela signifie que kubectl parvient à joindre l’API du cluster, preuve que la configuration réseau et le kubeconfig sont corrects.
Vérification du nœud et des pods système
Ensuite, on vérifie la disponibilité du nœud principal (dans le cas de Minikube, il n’y en a qu’un) :
kubectl get nodes -o wideLe nœud doit apparaître dans l’état Ready, ce qui signifie qu’il est apte à accueillir des pods. Une ligne typique pourrait ressembler à ceci :
root@debian-itconnect:~# kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
debian-itconnect Ready control-plane 34m v1.34.0 192.168.1.21 <none> Debian GNU/Linux 12 (bookworm) 6.1.0-40-amd64 docker://20.10.24+dfsg1Cette commande permet également de confirmer :
- La version exacte du noyau Linux et du runtime de conteneur (Docker ou containerd),
- L’adresse IP interne attribuée au nœud,
- Le rôle du nœud (control-plane dans le cas du cluster local).
Pour approfondir la vérification, il est conseillé d’afficher les pods système du namespace kube-system, où résident les services essentiels de Kubernetes :
root@debian-itconnect:~# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-66bc5c9577-wf2gn 1/1 Running 0 49m
coredns-66bc5c9577-wx9rc 1/1 Running 0 49m
etcd-debian-itconnect 1/1 Running 0 49m
kube-apiserver-debian-itconnect 1/1 Running 0 49m
kube-controller-manager-debian-itconnect 1/1 Running 1 (49m ago) 49m
kube-proxy-4k9mq 1/1 Running 0 49m
kube-scheduler-debian-itconnect 1/1 Running 0 49m
storage-provisioner 1/1 Running 0 49mParmi les pods attendus, on retrouve :
- coredns : assure la résolution DNS interne pour les pods,
- kube-proxy : gère les règles réseau entre les services et les pods,
- storage-provisioner : met à disposition un stockage persistant dynamique,
- etcd : base de données clé/valeur qui conserve l’état du cluster,
- kube-apiserver, kube-scheduler et kube-controller-manager : éléments centraux du plan de contrôle.
Tous ces pods doivent être dans l’état Running. Il est normal que certains mettent quelques secondes à se lancer juste après la création du cluster.
Déploiement d’une application de test
Pour valider concrètement que le cluster est opérationnel et que le plan de contrôle peut ordonner la création de pods, on effectue un déploiement simple. Par exemple, un serveur web Nginx :
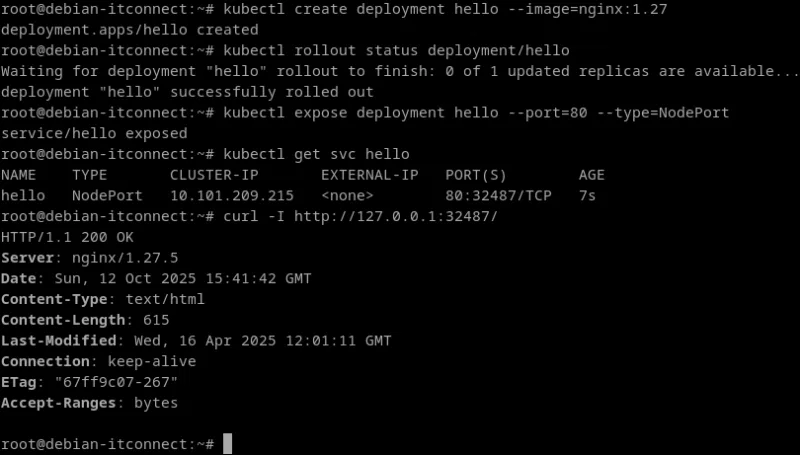
kubectl create deployment hello --image=nginx:1.27Cette commande ordonne à Kubernetes de créer un Deployment nommé hello et d’y exécuter un pod contenant le conteneur Nginx.
On peut suivre le déploiement et vérifier qu’il s’est bien déroulé avec :
kubectl rollout status deployment/helloLorsque le message deployment "hello" successfully rolled out apparaît, cela signifie que Kubernetes a bien programmé le pod sur le nœud, téléchargé l’image depuis Docker Hub et démarré le conteneur.
Vérification de l’accessibilité de l’application
L’application tourne désormais dans le cluster, mais elle n’est pas encore exposée à l’extérieur. Pour la rendre accessible, on crée un Service :
kubectl expose deployment hello --port=80 --type=NodePortCette ressource alloue un port réseau du nœud (appelé NodePort) qui redirige le trafic vers le port 80 du conteneur Nginx.
Pour identifier le port attribué :
kubectl get svc helloLa colonne PORT(S) affiche une valeur du type 80:32487/TCP, où 32487 est le port accessible depuis l’hôte. On peut alors tester l’accès localement :
curl -I http://127.0.0.1:32487/La réponse suivante indique que tout fonctionne correctement :
root@debian-itconnect:~# curl -I http://127.0.0.1:32487/
HTTP/1.1 200 OK
Server: nginx/1.27.5
Date: Sun, 12 Oct 2025 14:39:26 GMT
Content-Type: text/html
Content-Length: 615
Last-Modified: Wed, 16 Apr 2025 12:01:11 GMT
Connection: keep-alive
ETag: "67ff9c07-267"
Accept-Ranges: bytesCe simple test confirme que la couche réseau, le proxy kube-proxy, et le runtime de conteneur collaborent bien pour acheminer les requêtes.
Validation du stockage dynamique
Kubernetes s’appuie sur un addon appelé storage-provisioner, activé automatiquement par Minikube. Il crée des volumes persistants dynamiquement lorsqu’un pod en fait la demande. Pour s’assurer qu’il fonctionne, on peut exécuter :
kubectl get storageclassLe résultat attendu est :
root@debian-itconnect:~# kubectl get storageclass
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
standard (default) k8s.io/minikube-hostpath Delete Immediate false 73mCela signifie qu’une classe de stockage « standard » est bien disponible, ce qui garantit la possibilité de créer des volumes persistants dans les exercices à venir.
Surveillance et diagnostic du cluster
Une fois le cluster installé et fonctionnel, la phase suivante consiste à apprendre à surveiller son état et à diagnostiquer les problèmes susceptibles d’apparaître.
Dans un environnement Kubernetes, de nombreux composants interagissent en permanence : le plan de contrôle, les agents de nœuds, le réseau, le stockage, et bien sûr les applications déployées.
Savoir observer ces éléments et interpréter leurs signaux est une compétence essentielle pour tout administrateur.
Contrôler la santé des composants Kubernetes
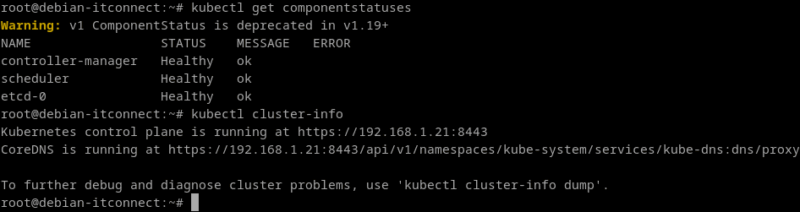
Kubernetes propose plusieurs outils intégrés pour vérifier la santé de ses différents modules. Tout d'abord, la commande suivante affiche un résumé du statut des composants principaux du plan de contrôle :
kubectl get componentstatusesOn y retrouve typiquement le scheduler, le controller-manager et etcd. Chaque ligne doit apparaître avec l’état Healthy. Si un composant est marqué comme Unhealthy, cela indique un problème de communication ou de performance interne (par exemple un etcd saturé ou un scheduler bloqué).
Une autre commande utile (déjà présentée) est :
kubectl cluster-infoElle permet de s’assurer que l’API serveur et le DNS interne sont accessibles. En cas d’erreur de type connection refused ou timeout, cela signale souvent un problème de réseau ou un kubelet arrêté.
Observation des ressources et métriques du cluster
La simple vérification de l’état des pods ne suffit pas ; il faut aussi surveiller leur consommation en ressources (CPU, mémoire, etc.). Pour cela, Kubernetes s’appuie sur un addon nommé metrics-server, qui collecte et agrège les métriques des nœuds et pods.
Si l’addon n’est pas encore activé, il suffit d’exécuter :
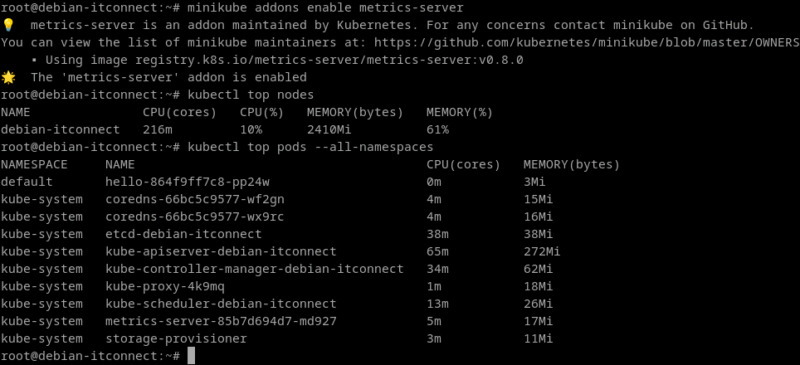
minikube addons enable metrics-serverQuelques secondes après, on peut consulter les métriques globales :
kubectl top nodesLa commande renvoie un tableau indiquant la charge CPU et mémoire de chaque nœud. De la même manière, pour les pods :
kubectl top pods --all-namespacesCes informations sont précieuses pour repérer les goulots d’étranglement : un pod consommant trop de mémoire, ou un nœud proche de la saturation, peuvent rapidement déséquilibrer le cluster.
Astuce : le metrics-server est indispensable pour activer des fonctionnalités comme l’auto-scaling automatique (HPA), car Kubernetes s’appuie sur ces données pour ajuster le nombre de réplicas.
Examiner les journaux et événements
Quand un pod rencontre une erreur ou ne démarre pas correctement, la lecture des journaux est essentielle. Chaque pod conserve ses propres logs accessibles via :
kubectl logs <nom_du_pod>Si plusieurs conteneurs cohabitent dans un même pod, on peut spécifier celui à examiner :
kubectl logs <nom_du_pod> -c <nom_du_conteneur>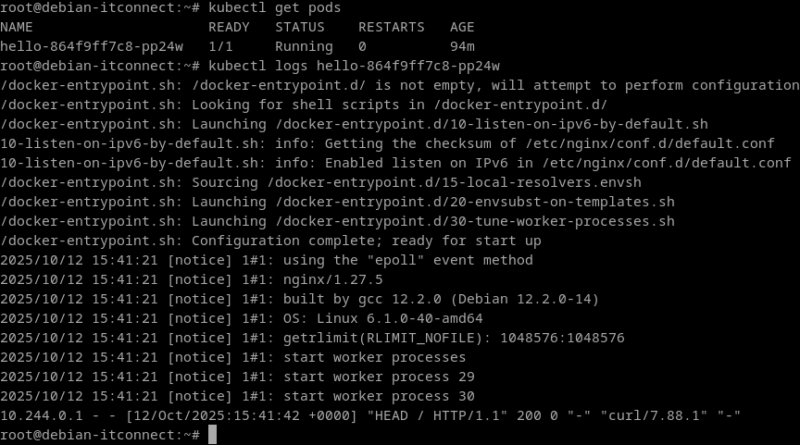
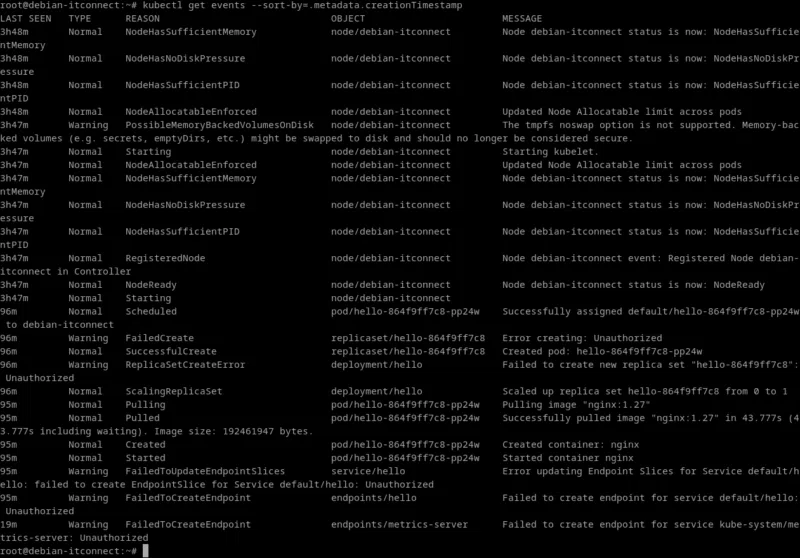
Pour comprendre l’historique d’un événement (création, planification, redémarrage, échec…), on peut également interroger Kubernetes sur les events :
kubectl get events --sort-by=.metadata.creationTimestampLes événements les plus récents apparaissent en bas de la liste. C’est souvent ici qu’on trouve la cause d’un crash ou d’un redémarrage en boucle (ex. : ImagePullBackOff, CrashLoopBackOff, OOMKilled).
Description détaillée des ressources
Lorsqu’une ressource ne se comporte pas comme prévu, la commande describe fournit une vue détaillée de sa configuration et de son état actuel.
Par exemple :
kubectl describe pod <nom_du_pod>Cette commande affiche la configuration complète du pod : les conteneurs, leurs images, les volumes montés, les labels, ainsi que les événements récents liés à ce pod. On y retrouve souvent la cause précise d’une erreur - un port bloqué, une image introuvable, ou une sonde de santé (liveness/readiness probe) qui échoue.
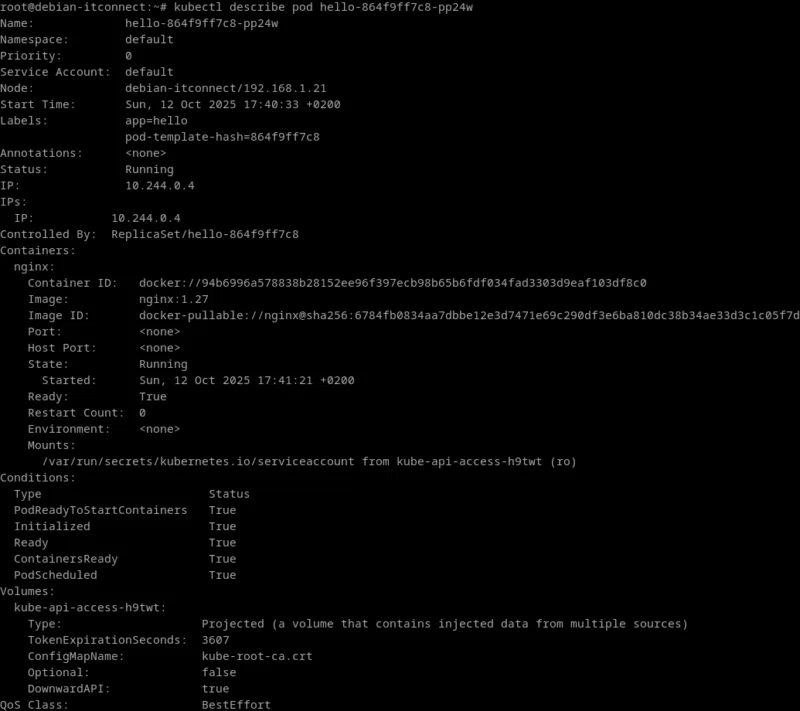
Diagnostic en cas de pod en échec
Un pod peut se retrouver bloqué dans des états tels que Pending, CrashLoopBackOff, ou ImagePullBackOff.
Voici quelques pistes de diagnostic :
- Pending : le pod n’a pas pu être planifié (souvent par manque de ressources ou de nœud disponible). Vérifiez les ressources avec kubectl describe pod ou kubectl get nodes.
- CrashLoopBackOff : le conteneur démarre, échoue, puis redémarre en boucle. Consultez les logs du conteneur pour identifier la cause exacte (erreur de configuration, dépendance manquante, etc.).
- ImagePullBackOff : Kubernetes n’arrive pas à télécharger l’image. Vérifiez le nom de l’image, la présence du registre, ou l’accès réseau.
- OOMKilled : le conteneur a dépassé sa limite mémoire (Out Of Memory). Il faut alors augmenter sa limite ou optimiser le processus qu’il exécute.
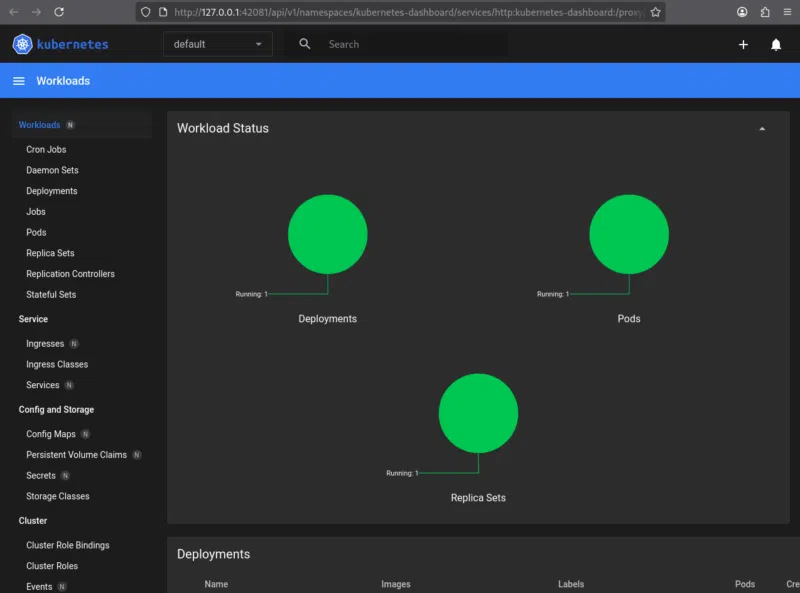
Surveillance visuelle : Kubernetes Dashboard
Pour une approche plus conviviale, Minikube propose un tableau de bord graphique. Il permet d’observer en temps réel l’état des ressources, des pods, et des métriques. Pour le lancer :
minikube dashboardCette commande ouvre une interface web locale dans le navigateur, qui se connecte directement à l’API du cluster.
Elle est très utile pour comprendre la structure du cluster, identifier les pods en échec et suivre visuellement l’évolution des déploiements.
Rendez-vous dès à présent dans le prochain chapitre pour poursuivre votre apprentissage.







