Surveillance et gestion des conteneurs en production
La mise en production d’applications conteneurisées marque une étape clé dans le cycle de vie d’un projet. Si les phases de développement et de test sont souvent bien maîtrisées, la véritable complexité apparaît lorsqu’il s’agit d’assurer la stabilité, la performance et la résilience des conteneurs sur la durée.
La surveillance et la gestion opérationnelle deviennent alors des piliers essentiels d’une infrastructure moderne. Dans un environnement Kubernetes ou Docker, il ne s’agit plus seulement de vérifier qu’un conteneur tourne, mais d’observer comment il se comporte, comment il consomme les ressources, et comment il interagit avec les autres composants du système.
Dans ce chapitre, nous aborderons les outils et les méthodes de monitoring les plus répandus (Prometheus, Grafana, cAdvisor), la gestion des logs dans Docker et Kubernetes, ainsi que les stratégies de surveillance proactive permettant d’anticiper les défaillances plutôt que de simplement les constater.
Sommaire
- Monitoring : comprendre les enjeux de la surveillance des conteneurs
- Les outils de monitoring des conteneurs
- Prometheus et Grafana : collecte et stockage des métriques
- Création de l’espace de travail « monitoring »
- Déploiement de Prometheus
- Déploiement de Grafana
- Installation de Grafana via Helm
- Déploiement de Prometheus
- Installation de Helm
- Installation de Grafana via Helm
- Exposer Grafana en NodePort
- Récupérer les identifiants d’administration
- Configurer Grafana pour utiliser Prometheus
- Gestion des logs dans Docker et Kubernetes
- Stratégies de surveillance proactive des performances
Monitoring : comprendre les enjeux de la surveillance des conteneurs
Les environnements conteneurisés reposent sur une logique hautement dynamique. Les conteneurs se créent, se suppriment et se redémarrent souvent automatiquement, parfois en quelques secondes.
Dans un tel contexte, les méthodes traditionnelles de supervision, qui consistaient à installer un agent sur un serveur physique pour en suivre les métriques, ne suffisent plus.
Les principaux enjeux sont les suivants :
- Visibilité complète : il est nécessaire de disposer d’une vue globale sur l’état du cluster, les performances des nœuds, l’état des pods, la consommation CPU et mémoire, ou encore les latences réseau.
- Corrélation des événements : les incidents ne se limitent plus à un serveur. Une défaillance peut provenir d’une interaction entre plusieurs services. L’observation doit donc pouvoir regrouper et corréler les données de différents niveaux : application, conteneur, nœud, cluster.
- Prévention et alertes : la supervision doit non seulement détecter une panne, mais aussi prévenir lorsqu’un seuil critique est sur le point d’être atteint.
- Automatisation et résilience : dans Kubernetes, la supervision peut déclencher des actions automatiques, comme le redémarrage de pods ou la montée en charge d’un déploiement.
Ces objectifs exigent des outils adaptés, capables de collecter, stocker et visualiser des volumes importants de données métriques en temps réel.
Les outils de monitoring des conteneurs
Trois outils se distinguent particulièrement dans les environnements Docker et Kubernetes : cAdvisor, Prometheus et Grafana. Ils sont souvent utilisés ensemble, formant une pile de surveillance complète et cohérente.
cAdvisor : le moniteur de conteneurs intégré
cAdvisor (Container Advisor) est un outil développé par Google, intégré nativement dans le moteur Docker et utilisé également dans Kubernetes. Son rôle est de collecter en continu les métriques relatives aux conteneurs exécutés sur un hôte : utilisation CPU, mémoire, E/S disque, trafic réseau, etc.
Sur notre machine debian-itconnect, disposant d’un cluster Minikube fonctionnel, cAdvisor peut être activé et visualisé facilement.
Principales caractéristiques de cAdvisor :
- Collecte automatique des métriques Docker sans configuration complexe.
- Interface web simple accessible sur le port 8080 par défaut.
- Exportation des métriques vers Prometheus.
- Intégration directe avec kubelet dans Kubernetes.
Sur notre machine, il est possible de déployer rapidement cAdvisor dans un conteneur Docker isolé.
La variable VERSION doit correspondre à la dernière version stable publiée sur la page GitHub du projet :
Exécutons la commande suivante :
VERSION=v0.52.1
docker run \
--volume=/:/rootfs:ro \
--volume=/var/run:/var/run:ro \
--volume=/sys:/sys:ro \
--volume=/var/lib/docker/:/var/lib/docker:ro \
--volume=/dev/disk/:/dev/disk:ro \
--publish=8080:8080 \
--detach=true \
--name=cadvisor \
--privileged \
--device=/dev/kmsg \
gcr.io/cadvisor/cadvisor:$VERSION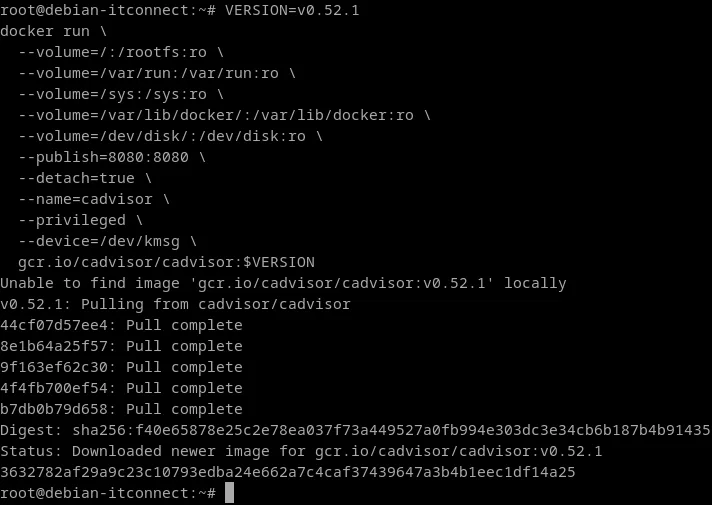
Décryptons cette commande pour comprendre chaque paramètre :
--volume=/:/rootfs:ro: monte le système de fichiers racine de l’hôte en lecture seule, afin que cAdvisor puisse y lire les informations de ressources globales.--volume=/var/run:/var/run:ro: donne accès aux sockets Docker et aux informations de runtime.--volume=/sys:/sys:ro: permet de lire les statistiques du noyau (CPU, mémoire, cgroups).--volume=/var/lib/docker/:/var/lib/docker:ro: donne accès à l’état interne des conteneurs Docker.--volume=/dev/disk/:/dev/disk:ro: collecte les informations sur les périphériques de stockage.--publish=8080:8080: expose l’interface web et l’API de métriques sur le port 8080.--detach=true: exécute cAdvisor en tâche de fond.--name=cadvisor: nomme le conteneur.--privilegedet--device=/dev/kmsg: donnent à cAdvisor les permissions nécessaires pour lire les journaux du noyau Linux.
Une fois le conteneur lancé, vérifions son état :
docker psNous devrions voir une ligne similaire à :
root@debian-itconnect:~# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3632782af29a gcr.io/cadvisor/cadvisor:v0.52.1 "/usr/bin/cadvisor -…" 6 minutes ago Up 6 minutes (healthy) 0.0.0.0:8080->8080/tcp, :::8080->8080/tcp cadvisor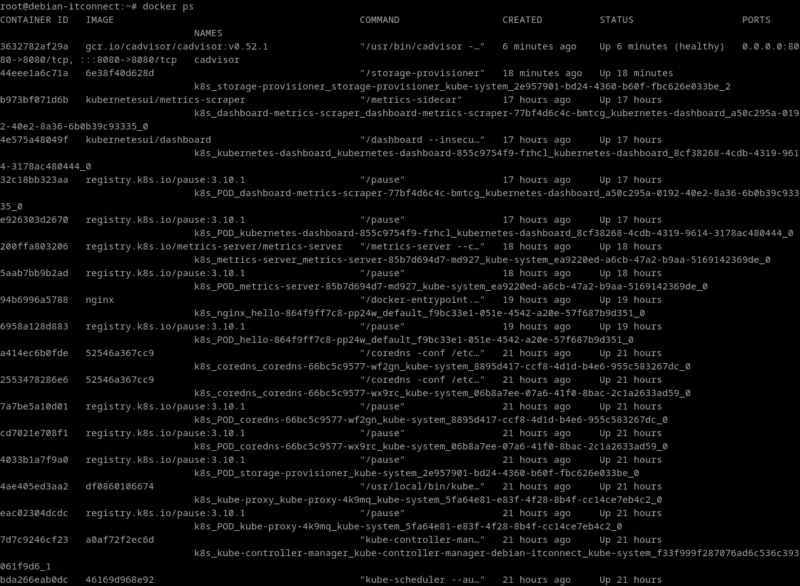
L’interface web est maintenant accessible depuis le navigateur à l’adresse : http://localhost:8080.
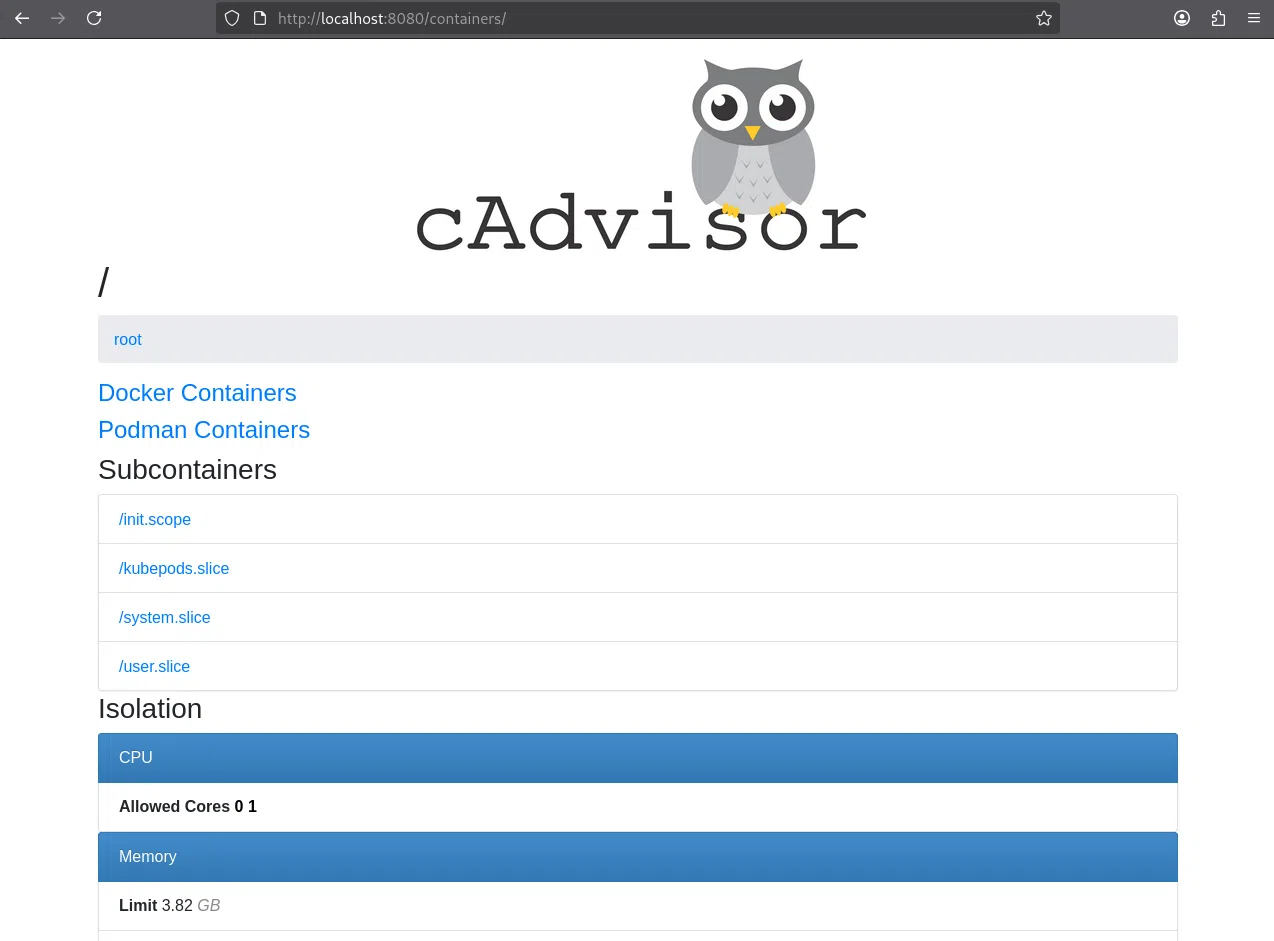
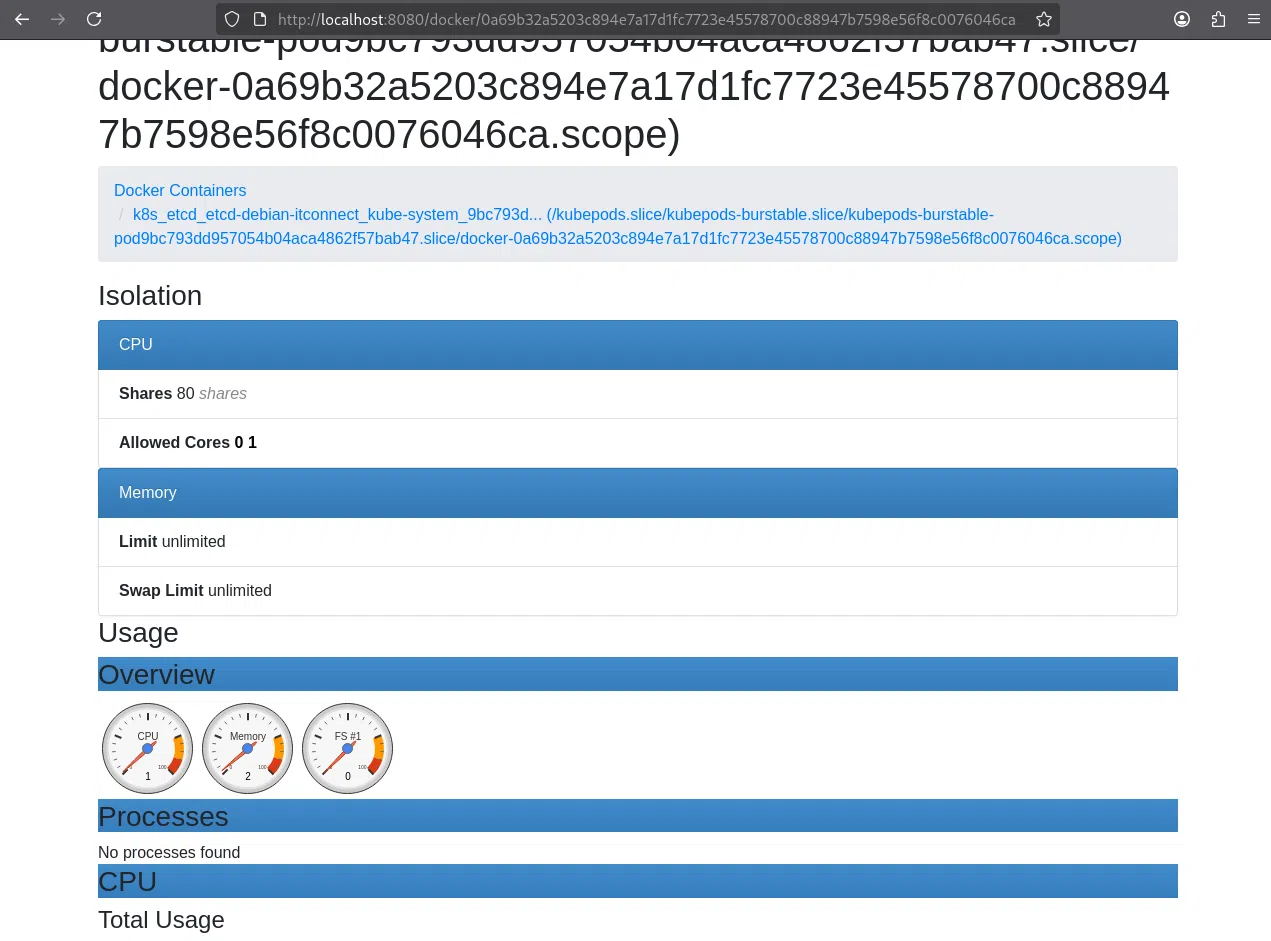
Nous y trouvons un tableau de bord en temps réel listant tous les conteneurs en cours d’exécution, leurs statistiques CPU, mémoire, I/O disque, et réseau.
Chaque conteneur dispose également d’une page détaillée affichant ses métriques historiques. cAdvisor expose ses métriques sur l’endpoint suivant : http://localhost:8080/metrics.
Ce point d’entrée est compatible avec Prometheus, ce qui permet à ce dernier de scraper automatiquement les données et de les stocker dans sa base interne.
Dans un environnement Kubernetes, cette intégration est souvent configurée par défaut via les ServiceMonitors du Prometheus Operator. Ainsi, cAdvisor agit comme une sonde locale, Prometheus comme un collecteur global, et Grafana comme un tableau de bord centralisé.
Prometheus et Grafana : collecte et stockage des métriques
Prometheus est la pierre angulaire du monitoring moderne dans les clusters Kubernetes. Il est capable d’interroger périodiquement des endpoints /metrics exposés par les services et d’enregistrer les valeurs observées dans une base de données de séries temporelles.
Nous allons maintenant installer Prometheus et Grafana directement sur notre cluster Minikube, déjà actif sur notre machine.
Ces deux outils forment le cœur de la supervision moderne dans les environnements Kubernetes :
- Prometheus est chargé de collecter et stocker les métriques techniques (CPU, mémoire, réseau, état des pods, etc.) à partir des différents composants du cluster.
- Grafana, quant à lui, se connecte à Prometheus pour interpréter et visualiser ces données sous forme de tableaux de bord dynamiques, de graphiques et d’indicateurs clairs permettant une analyse rapide de l’état du système.
L’objectif est donc de mettre en place un environnement complet d’observabilité, capable non seulement de mesurer les performances du cluster, mais aussi de les représenter visuellement pour faciliter le diagnostic et le suivi des tendances dans le temps.
L’installation que nous allons effectuer repose sur les manifests Kubernetes officiels (fichiers YAML), comme expliqué dans la documentation de référence.
Cette approche a l’avantage d’être à la fois transparente et pédagogique, car elle permet de comprendre la fonction de chaque composant déployé : ConfigMap, Service, Deployment et DaemonSet, tout en posant les bases d’une architecture de supervision robuste et extensible.
Création de l’espace de travail « monitoring »
Avant de déployer Prometheus et Grafana, il est essentiel d’organiser notre cluster de manière logique. Dans Kubernetes, la bonne pratique consiste à regrouper les ressources ayant une fonction commune dans un namespace dédié.
Nous allons donc créer un espace nommé monitoring, qui servira exclusivement à héberger les composants liés à la supervision du cluster, à savoir Prometheus (collecte et stockage des métriques) et Grafana (visualisation et analyse des données).
Ce namespace permettra :
- De centraliser la configuration et les ressources de monitoring
- De faciliter la maintenance et la mise à jour des outils d’observabilité
- Et d’éviter tout risque de confusion avec les applications déployées dans d’autres espaces du cluster
Créons ce namespace avec la commande suivante :
kubectl create namespace monitoringVérifions que le namespace est bien créé :
kubectl get nsUne nouvelle ligne devrait apparaître :
root@debian-itconnect:~# kubectl get ns
NAME STATUS AGE
default Active 4d1h
kube-node-lease Active 4d1h
kube-public Active 4d1h
kube-system Active 4d1h
kubernetes-dashboard Active 3d21h
monitoring Active 6s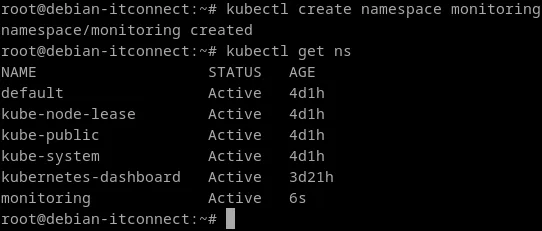
Déploiement de Prometheus
Prometheus est constitué de plusieurs éléments :
- Un Deployment qui exécute le serveur Prometheus,
- Un Service pour l’exposer,
- Et un ConfigMap pour définir la configuration de scraping.
Commençons par créer le fichier prometheus-config.yaml :
nano prometheus-config.yamlEt ajoutons le contenu suivant :
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-server-conf
namespace: monitoring
labels:
name: prometheus-server-conf
data:
prometheus.yml: |
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'kubernetes-nodes'
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels:
[__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $1:$2
target_label: __address__Ce fichier définit les règles de scraping : Prometheus interrogera automatiquement les nœuds et les pods qui exposent des métriques au format /metrics.
Appliquons ce ConfigMap :
kubectl apply -f prometheus-config.yamlCréons maintenant le fichier prometheus-deployment.yaml :
nano prometheus-deployment.yamlContenu :
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-deployment
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app: prometheus
template:
metadata:
labels:
app: prometheus
spec:
containers:
- name: prometheus
image: prom/prometheus:v2.51.2
args:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus/"
ports:
- containerPort: 9090
volumeMounts:
- name: prometheus-config-volume
mountPath: /etc/prometheus/
- name: prometheus-storage-volume
mountPath: /prometheus/
volumes:
- name: prometheus-config-volume
configMap:
name: prometheus-server-conf
- name: prometheus-storage-volume
emptyDir: {}Ce déploiement lance un pod contenant Prometheus Server, avec deux volumes :
- Un volume ConfigMap contenant la configuration,
- Un volume temporaire pour stocker les données des métriques.
Appliquons ce manifest :
kubectl apply -f prometheus-deployment.yamlPour accéder à l’interface web, nous créons un Service :
nano prometheus-service.yamlContenu :
apiVersion: v1
kind: Service
metadata:
name: prometheus-service
namespace: monitoring
spec:
type: NodePort
selector:
app: prometheus
ports:
- port: 9090
targetPort: 9090
nodePort: 30000Appliquons :
kubectl apply -f prometheus-service.yamlVérifions que le pod est bien en fonctionnement :
kubectl get pods -n monitoringNous devrions voir une ligne similaire à :
root@debian-itconnect:~# kubectl get pods -n monitoring
NAME READY STATUS RESTARTS AGE
prometheus-deployment-6cdcf99b75-dp6c9 1/1 Running 0 16mEt que le service est bien exposé :
kubectl get svc -n monitoringNous devrions voir un port NodePort 30000 :
root@debian-itconnect:~# kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus-service NodePort 10.110.33.194 <none> 9090:30000/TCP 22s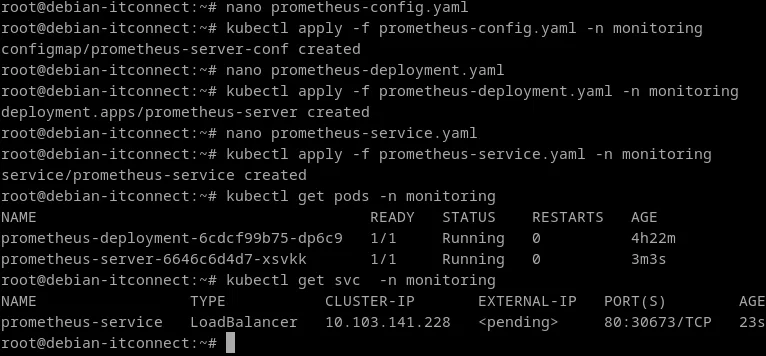
Déploiement de Grafana
Prometheus collecte et stocke les métriques, mais pour les analyser efficacement, il faut une interface graphique. C’est le rôle de Grafana, qui permet de créer des tableaux de bord dynamiques et des visualisations.
Créons le fichier grafana-deployment.yaml :
nano grafana-deployment.yamlContenu :
apiVersion: apps/v1
kind: Deployment
metadata:
name: grafana
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app: grafana
template:
metadata:
labels:
app: grafana
spec:
containers:
- name: grafana
image: grafana/grafana:10.2.2
ports:
- containerPort: 3000
env:
- name: GF_SECURITY_ADMIN_USER
value: "admin"
- name: GF_SECURITY_ADMIN_PASSWORD
value: "admin"Appliquons :
kubectl apply -f grafana-deployment.yamlCréons le fichier grafana-service.yaml :
nano grafana-service.yamlContenu :
apiVersion: v1
kind: Service
metadata:
name: grafana-service
namespace: monitorin
spec:
type: NodePort
selector:
app: grafana
ports:
- port: 3000
targetPort: 3000
nodePort: 31000Appliquons :
kubectl apply -f grafana-service.yamlVérifions :
kubectl get pods -n monitoring
kubectl get svc -n monitoringNous devrions obtenir :
root@debian-itconnect:~# kubectl get pods -n monitoring
NAME READY STATUS RESTARTS AGE
grafana-54f5db75c5-8l7cc 1/1 Running 0 13m
prometheus-deployment-6cdcf99b75-dp6c9 1/1 Running 0 44m
root@debian-itconnect:~# kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
grafana-service NodePort 10.105.58.23 <none> 3000:31000/TCP 13m
prometheus-service NodePort 10.110.33.194 <none> 9090:30000/TCP 44mL’interface de Grafana sera disponible à l’adresse suivante : http://<IP_Minikube>:31000.
L’IP peut être affichée via la commande :
minikube ip
Les identifiants par défaut sont les suivants : admin / admin.
Une fois connecté à Grafana :
- Cliquons sur “Add data source”
- Choisir Prometheus
- Dans l’URL, indiquons : http://prometheus-service.monitoring.svc.cluster.local:9090
- Confirmer avec "Save & Test"
Si tout est correctement configuré, Grafana affichera “Data source is working”.
Installation de Grafana via Helm
Nous allons maintenant installer Grafana, l’outil de visualisation complémentaire à Prometheus.
Grafana joue un rôle essentiel dans une infrastructure de supervision : là où Prometheus collecte et stocke les métriques, Grafana les interprète et les transforme en tableaux de bord dynamiques, faciles à lire et à personnaliser.
Pour cette installation, nous allons suivre une méthode moderne et flexible : le déploiement via Helm, le gestionnaire de packages de Kubernetes.
Helm simplifie considérablement le déploiement des applications complexes : il automatise la création des Deployments, Services, Secrets et autres objets nécessaires à l’exécution d’un service complet.
Nous allons donc ajouter le dépôt officiel de Grafana, puis installer la version stable de l’application directement dans notre namespace monitoring.
Commençons par référencer le dépôt officiel Grafana :
helm repo add grafana https://grafana.github.io/helm-charts
helm repo updateDéploiement de Prometheus
Créer le fichier prometheus-config.yaml avec exactement le contenu suivant :
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-server-conf
namespace: monitorin
data:
prometheus.yml: |
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']Appliquons :
kubectl apply -f prometheus-config.yaml -n monitoringEnsuite, créons le fichier prometheus-deployment.yaml :
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-server
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app: prometheus-server
template:
metadata:
labels:
app: prometheus-server
spec:
containers:
- name: prometheus
image: prom/prometheus
ports:
- containerPort: 9090
volumeMounts:
- name: config-volume
mountPath: /etc/prometheus
volumes:
- name: config-volume
configMap:
name: prometheus-server-conf
defaultMode: 420Appliquons :
kubectl apply -f prometheus-deployment.yaml -n monitoringCréons le fichier prometheus-service.yaml :
apiVersion: v1
kind: Service
metadata:
name: prometheus-service
namespace: monitoring
spec:
selector:
app: prometheus-server
ports:
- protocol: TCP
port: 80
targetPort: 9090
type: LoadBalancerAppliquons :
kubectl apply -f prometheus-service.yaml -n monitoringVérifions que le pod est bien en fonctionnement :
kubectl get pods -n monitoringEt que le service est bien exposé :
kubectl get svc -n monitoringInstallation de Helm
Avant d’installer Grafana via Helm, il est nécessaire de disposer de Helm, le gestionnaire de paquets officiel de Kubernetes.
Helm simplifie le déploiement des applications complexes en regroupant l’ensemble des manifestes YAML d’un projet (Deployments, Services, ConfigMaps, Secrets, etc.) dans des charts facilement installables, mis à jour et supprimés.
La méthode la plus directe pour installer Helm v3 consiste à exécuter le script officiel du projet Helm. Cette approche télécharge la dernière version stable adaptée à l’OS/architecture et place le binaire helm dans un répertoire du $PATH.
Téléchargeons le script d’installation :
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3Rendons le script exécutable :
chmod 700 get_helm.shPuis exécutons le script :
./get_helm.shLe script détecte automatiquement la plate-forme (Linux/amd64, etc.), télécharge l’archive correspondante et installe helm (par défaut dans /usr/local/bin/helm si possible).
Vérifions l’installation :
helm versionLa commande doit afficher une sortie similaire à :
root@debian-itconnect:~# helm version
version.BuildInfo{Version:"v3.19.0", GitCommit:"3d8990f0836691f0229297773f3524598f46bda6", GitTreeState:"clean", GoVersion:"go1.24.7"}
Installation de Grafana via Helm
Dans cette étape, nous allons installer Grafana, l’outil de visualisation et d’analyse des métriques collectées par Prometheus.
Grafana est déployé dans le namespace monitoring déjà créé, à l’aide du gestionnaire de paquets Helm, désormais installé sur notre machine.
Commençons par ajouter le dépôt officiel de Grafana :
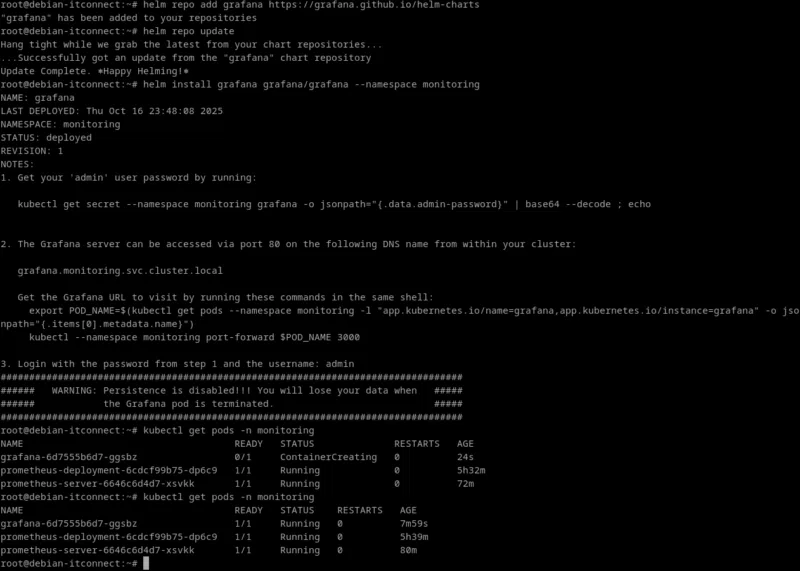
helm repo add grafana https://grafana.github.io/helm-charts
helm repo updateLa première commande ajoute le dépôt à la configuration locale d’Helm, et la seconde actualise la liste des charts disponibles.
Nous lançons ensuite l’installation du chart Grafana directement dans le namespace monitoring :
helm install grafana grafana/grafana --namespace monitoringCette commande :
- Télécharge le chart Grafana depuis le dépôt Helm
- Crée automatiquement un Deployment, un Service, et un Secret contenant le mot de passe administrateur
- Et déploie un pod Grafana dans le namespace monitoring
Vérifions l’état des pods :
kubectl get pods -n monitoringVous devriez obtenir un résultat similaire à celui-ci :
root@debian-itconnect:~# kubectl get pods -n monitoring
NAME READY STATUS RESTARTS AGE
grafana-6d7555b6d7-ggsbz 1/1 Running 0 7m59sLorsque le pod grafana-xxxxx affiche STATUS = Running, l’installation est réussie.
Exposer Grafana en NodePort
Par défaut, Grafana est créé avec un Service de type ClusterIP, c’est-à-dire accessible uniquement à l’intérieur du cluster Kubernetes.
Pour pouvoir consulter l’interface web depuis l’extérieur, nous devons créer un Service de type NodePort :
kubectl expose service grafana --type=NodePort --target-port=3000 --name=grafana-ext -n monitoringCette commande crée un nouveau service nommé grafana-ext qui redirige le port 3000 du conteneur Grafana vers un port aléatoire ouvert sur le nœud Minikube.
Pour obtenir l’adresse exacte, exécutons :
minikube service grafana-ext -n monitoringMinikube affichera et ouvrira automatiquement l’URL du tableau de bord Grafana.
Problème possible lors de l’accès à Grafana : il est possible, selon la configuration de ton cluster Minikube, que l’interface Grafana n’arrive pas à charger ses fichiers statiques (CSS, JS, images) après l’exposition du service avec la commande kubectl expose service grafana --type=NodePort.
Dans ce cas, le navigateur affiche le message : « Grafana has failed to load its application files ».
Ce comportement n’indique pas une erreur d’installation, mais un problème de redirection entre le service NodePort et le serveur Grafana : les chemins de fichiers ne correspondent plus au root_url attendu.
La documentation Helm de Grafana (et les notes affichées lors de l’installation) préconisent d’utiliser le port-forward pour accéder à l’interface Web de manière fiable :
export POD_NAME=$(kubectl get pods -n monitoring -l "app.kubernetes.io/name=grafana,app.kubernetes.io/instance=grafana" -o jsonpath="{.items[0].metadata.name}")
kubectl port-forward -n monitoring $POD_NAME 3000Tant que ce terminal reste ouvert, le port 3000 de la machine est relié au port 3000 du conteneur Grafana.

Nous ouvrons alors dans notre navigateur : http://localhost:3000. Nous accédons ainsi directement à l’interface complète de Grafana, sans erreur de chargement.
Récupérer les identifiants d’administration
Le chart Helm Grafana génère automatiquement un mot de passe pour le compte administrateur (admin). Ce mot de passe est stocké dans un Secret Kubernetes.
Pour l’afficher :
kubectl get secret grafana -n monitoring \
-o jsonpath='{.data.admin-password}' | base64 -d; echo
Nous pouvons ensuite nous connecter à l’URL obtenue précédemment avec ces identifiants.
Configurer Grafana pour utiliser Prometheus
Grafana dispose d’une vaste bibliothèque de dashboards publics accessibles depuis son interface.
Dans la barre latérale gauche :
1. Nous cliquons sur « Connections » puis sur « Data sources ».
2. Nous sélectionnons « Add data source ».
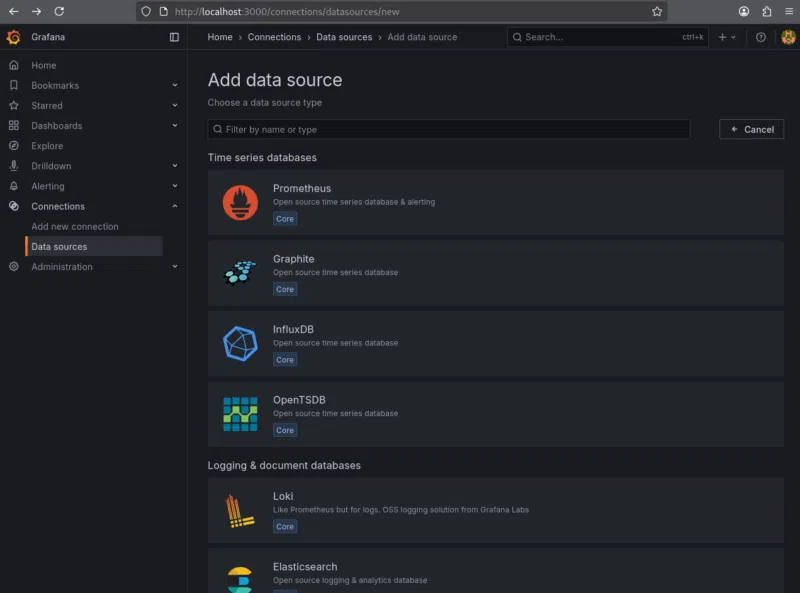
3. Nous choisissons « Prometheus » dans la liste des options proposées.
Dans la page de configuration qui s’ouvre :
- Name : laissons la valeur par défaut (prometheus).
- URL : saisissons l’adresse interne du service Prometheus du cluster : http://prometheus-service:80
- Cette URL correspond au nom DNS Kubernetes du service Prometheus exposé précédemment (dans le namespace monitoring), suivi du port 80.
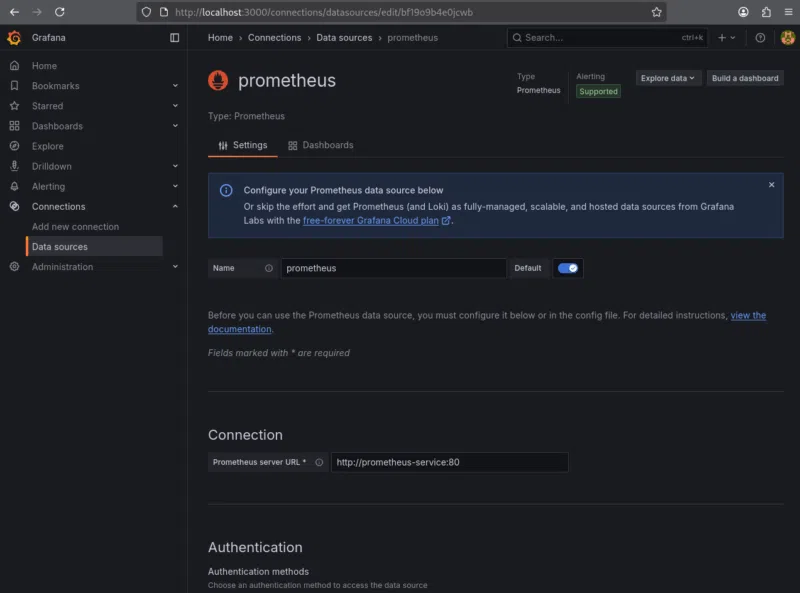
Nous déroulons la page jusqu’à « Save & test ». Si la configuration est correcte, Grafana affiche le message : « Successfully queried the Prometheus API. »
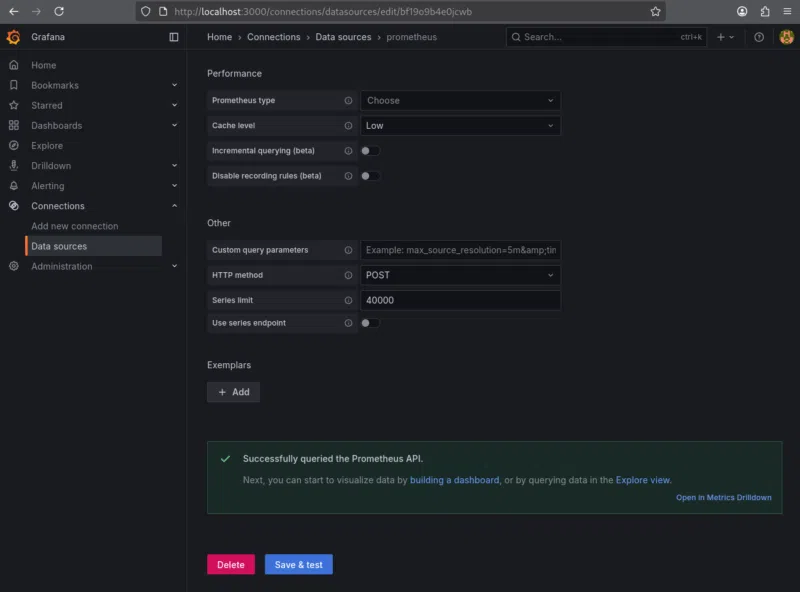
Cela confirme que la connexion entre Grafana et Prometheus est opérationnelle.
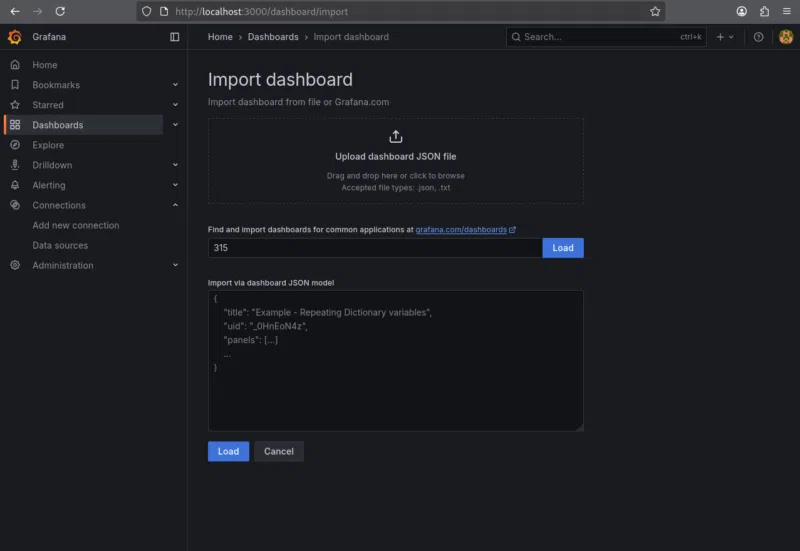
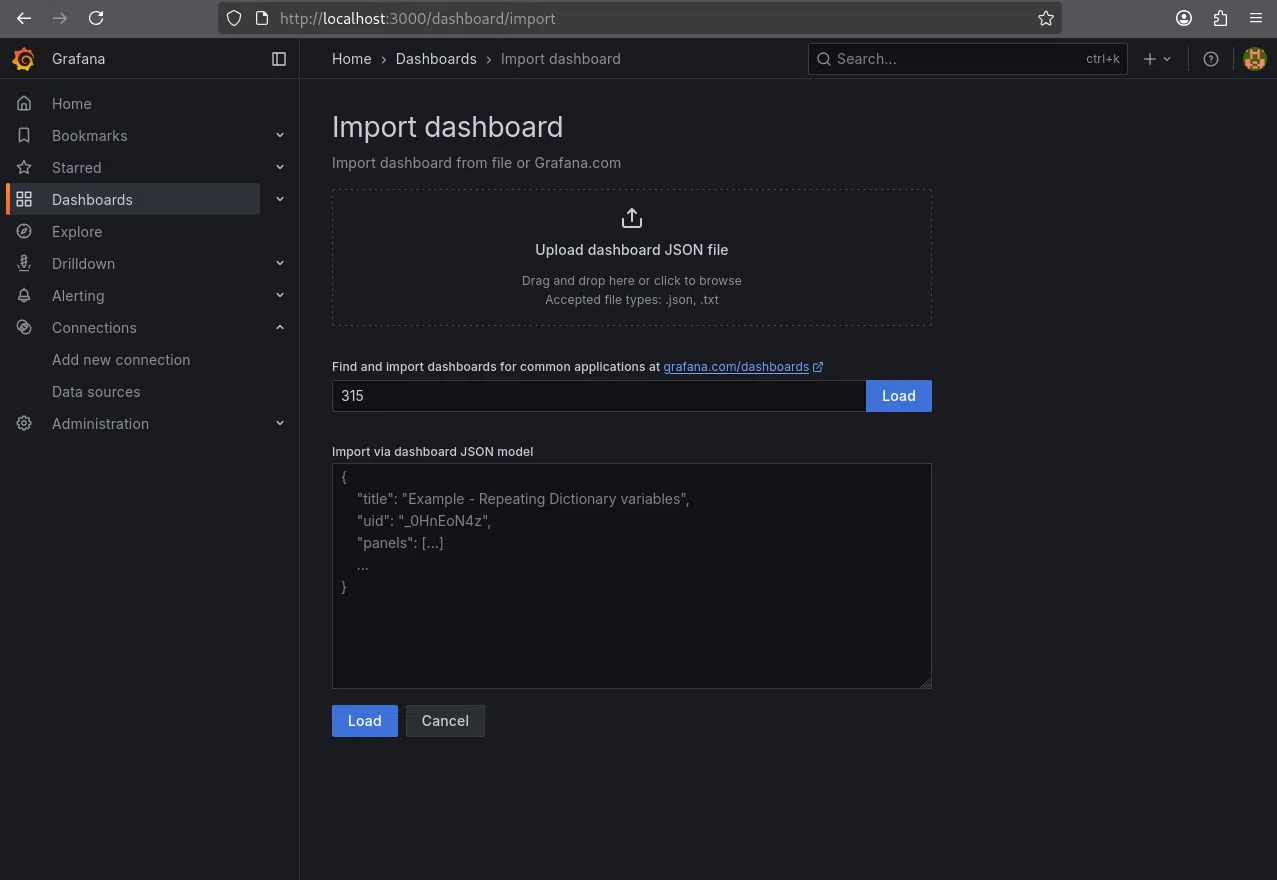
Après cette étape, nous allons importer un dashboard existant. Depuis le menu de gauche de Grafana :
- Cliquons sur « Dashboard »
- Ensuite, nous cliquons en haut à droite « New -> Import »
- Nous saisissons l’ID du tableau de bord que nous souhaitons importer, par exemple 315, un modèle générique et efficace pour la supervision Kubernetes
- Cliquons sur « Load »
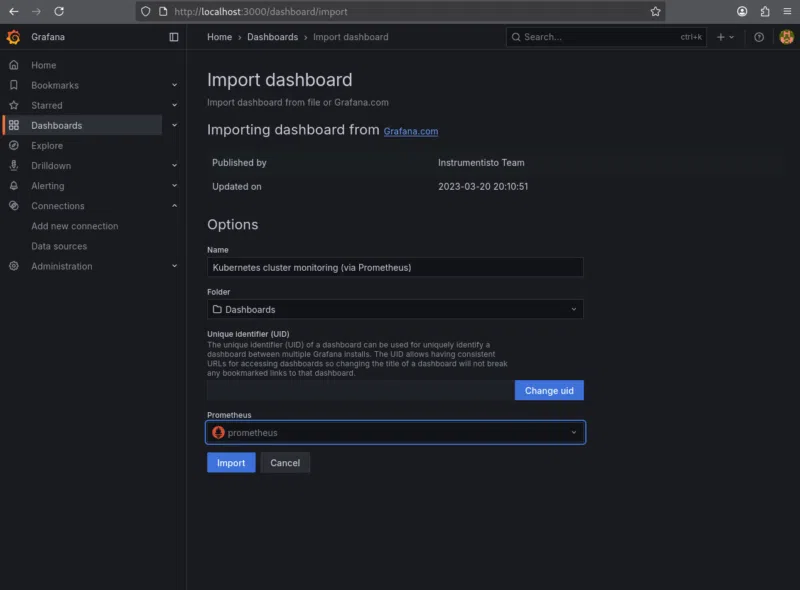
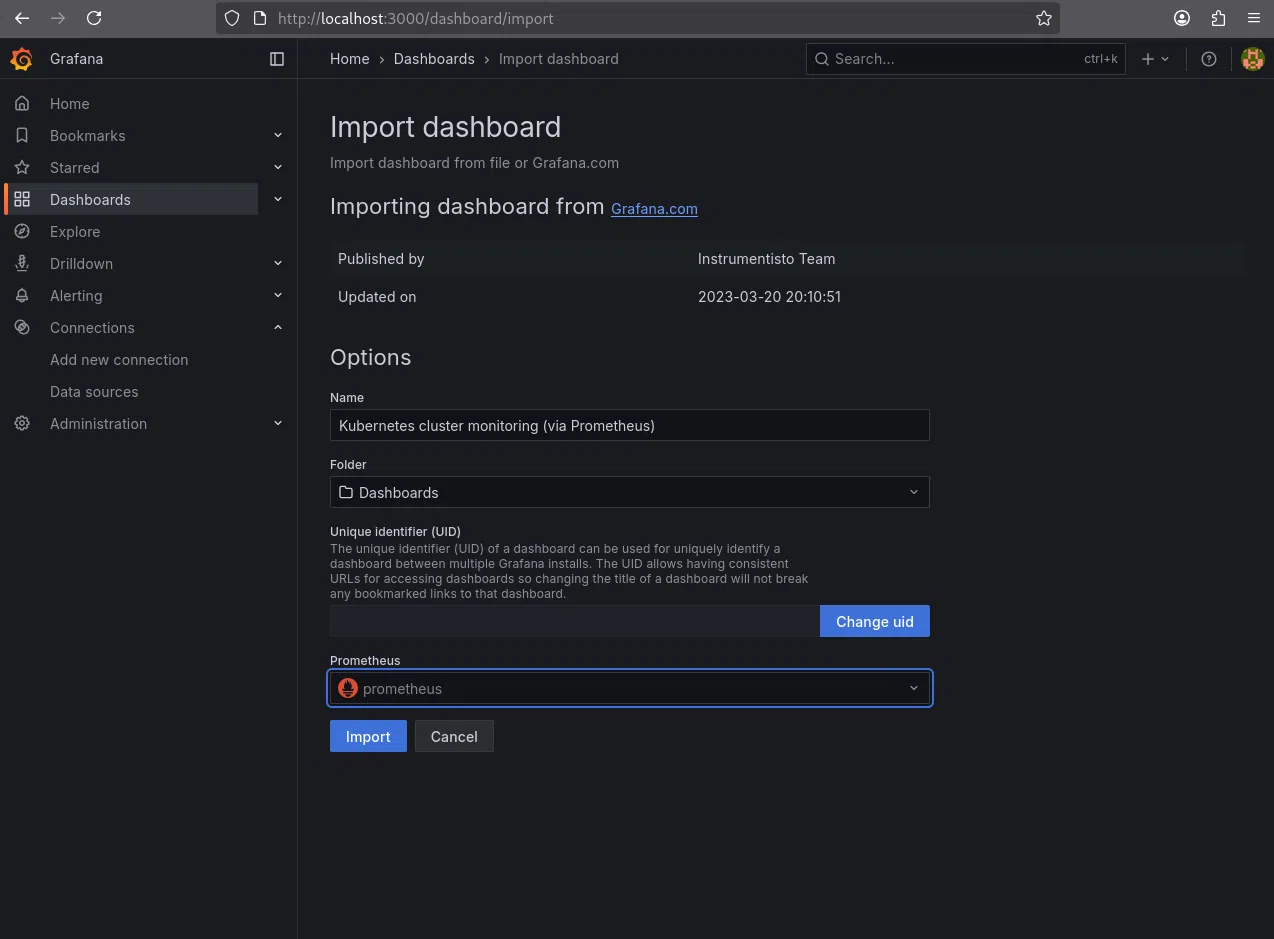
- Nous sélectionnons la source de données Prometheus créée précédemment.
- Nous importons
Le tableau de bord s’affiche alors immédiatement à l’écran. Il affiche en temps réel les métriques suivantes :
- La consommation CPU et mémoire des nœuds et des pods
- Le nombre total de conteneurs en cours d’exécution
- L’état du cluster (Running / Pending / CrashLoopBackOff)
- La charge moyenne sur les différents nœuds
- Les latences réseau et taux de paquets
- Et d’autres métriques exposées par Prometheus
Chaque panneau peut être personnalisé : nous pouvons modifier la période de rafraîchissement, filtrer par namespace ou pod, et ajouter nos propres visualisations selon nos besoins.
Gestion des logs dans Docker et Kubernetes
Les logs Docker
Les logs sont une composante essentielle du diagnostic en production.
Chaque conteneur Docker dispose de sa propre sortie standard (stdout) et erreur standard (stderr), que le démon Docker collecte automatiquement.
Pour visualiser les logs d’un conteneur spécifique :
docker logs <nom_du_conteneur>L’option -f permet de suivre les logs en temps réel :
docker logs -f <nom_du_conteneur>Docker propose plusieurs drivers de logs, configurables dans le fichier /etc/docker/daemon.json :
json-file: format par défaut, les logs sont stockés en JSON sur le disque localsyslog: envoie les logs au démon syslog du systèmefluentd: intégration avec Fluentd, souvent utilisé pour le centralisergelf,awslogs,splunk: permettent d’envoyer les logs vers des systèmes externes
Une bonne pratique consiste à rediriger les logs Docker vers une solution centralisée, afin d’éviter la perte d’informations lors de la suppression d’un conteneur.
Les logs Kubernetes
Dans Kubernetes, la gestion des logs est plus complexe, car les pods sont éphémères et peuvent être recréés automatiquement.
Chaque pod possède ses propres flux de logs, accessibles avec :
kubectl logs <nom_du_pod>Pour un pod comportant plusieurs conteneurs :
kubectl logs <nom_du_pod> -c <nom_du_conteneur>Lorsqu’un pod a été redémarré, l’option --previous permet d’accéder aux logs du conteneur précédent.
Centralisation des logs de Kubernetes
Kubernetes ne stocke pas les logs de manière persistante. En production, il est donc essentiel de déployer une solution de log management. Plusieurs approches existent :
- EFK Stack (Elasticsearch + Fluentd + Kibana) : collecteur, moteur d’indexation et interface web de recherche
- Loki + Promtail + Grafana : alternative légère conçue par Grafana Labs
- Solutions SaaS : Datadog, Logz.io, Splunk Cloud, etc
Ces systèmes permettent d’effectuer des recherches croisées, de filtrer les événements par application, namespace ou conteneur, et de corréler logs et métriques.
Stratégies de surveillance proactive des performances
Surveiller, c’est bien ; anticiper, c’est mieux.
Une stratégie de surveillance proactive vise à prévenir les incidents avant qu’ils n’impactent l’utilisateur final. Cela implique non seulement de collecter des métriques, mais aussi de les analyser dans le temps, de définir des seuils, et de déclencher des alertes automatiques.
Définir les indicateurs pertinents
Prometheus permet de définir des règles d’alerte dans ses fichiers de configuration (alert.rules).
Par exemple :
groups:
- name: container_alerts
rules:
- alert: HighMemoryUsage
expr: container_memory_usage_bytes > 500000000
for: 5m
labels:
severity: warning
annotations:
summary: "Utilisation mémoire élevée sur {{ $labels.container }}"Ces alertes peuvent être transmises à Alertmanager, qui se charge d’envoyer des notifications par e-mail, Slack, ou via une API tierce.
Corrélation entre métriques et logs
L’efficacité d’une supervision repose sur la corrélation entre métriques et logs. Lorsqu’une alerte est déclenchée, il est crucial de pouvoir remonter immédiatement aux logs correspondants afin de comprendre la cause profonde du problème.
C’est pourquoi de nombreuses entreprises utilisent la pile Prometheus + Grafana + Loki, qui permet d’afficher simultanément des graphiques de performance et des logs associés dans une seule interface.