Curl, l’outil testeur des protocoles divers
Sommaire
I. Présentation
Lorsque l’on travaille sous des distributions Linux, il arrive fréquemment que l’on soit confronté à la validation du fonctionnement de tel ou tel protocole. On oublie souvent qu’il existe un outil polyvalent, permettant non seulement d’effectuer du téléchargement mais également de tester les différents protocoles ci-dessous (entre autres):
- FTP (et/ou FTPS)
- HTTP (et/ou HTTPS)
- SCP
- TFTP
- …
II. L'outil curl
Curl est un outil open source, en ligne de commande permettant effectivement de télécharger n’importe quels fichiers via les divers protocoles mentionnés ci-dessus. Il est très léger et fonctionne sur pratiquement n’importe quelle plateforme : MAC, Windows, Linux. Il m’est déjà arrivé de l’utiliser dans des scripts, sous Linux pour télécharger du contenu. Mais, on oubli très souvent que cet outil permet également de faire un diagnostic précis, de tester ou "benchmarker" des applications. Nous verrons au travers de quelques exemples que l’on peut tester chaque fonction web :
- GET
- POST
- PUT
- DELETE
- …
On peut aussi lui faire exécuter des tâches de maintenance comme de la sauvegarde de fichiers ou encore l’envoi de dossiers au travers d’un site FTP, et ce, en traversant des protocoles sécurisés tels que HTTPS, SFTP, etc.
III. Fonction de téléchargement
Certes, curl permet en premier lieu de télécharger du contenu selon plusieurs protocoles. C’est ce que l’on va voir dans ce paragraphe. De façon standard, on peut facilement télécharger des fichiers HTTP (ou FTP) grâce à ce petit outil, en exécutant l’une des commandes suivantes :
$ curl –o myfile.ext http://site.mydmn.org/fichier.rpm
Exemple: télécharger un package curlpp via un dépôt site.mydmn.org:
$ curl –o myfile.ext http://site.mydmn.org/repo/epel/curlpp-0.7.3-5.el6.x86_64.rpm
On trouve alors dans le fichier myfile.ext le résultat de l’opération. Si le fichier a été correctement téléchargé le contenu du fichier de trace est illisible car exprimé en binaire. Bien évidemment, on peut également récupérer une page HTML complète depuis un site web :
$ curl –o mypage.html http://www.mysite.org/page.html
Pour télécharger plusieurs fichiers en une seule fois, il suffit d’utiliser la directive –O pour chaque fichier à récupérer:
$ curl –O http://site.mydmn.org/file1 -O http://site.mydmn.org/file2
REMARQUE: Si l’on souhaite télécharger un fichier, sans pour autant disposer d’un fichier de trace, on peut simplement lancer la commande suivante, réalisant le téléchargement :
$ curl --remote-name http://site.mydmn.org/repo/epel/curlpp-0.7.3-5.el6.x86_64.rpm
Bien entendu, cela fonctionne aussi pour des protocoles autres que HTTP ou HTTPS, tels que SSH, par exemple. Supposons que l’on souhaite télécharger un fichier au travers de SSH et du protocole SFTP, on devra alors exécuter la commande :
$ curl –u phil sftp://site-ssh.mydmn.org/file01
De la même façon, en appliquant ce principe, on peut alors télécharger un fichier de clé SSH, en utilisant la commande curl au travers du protocole de copie sécurisé scp:
$ curl –u phil: --key ~/.ssh/id_rsa --pubkey ~/.ssh/id_rsa.pub scp://site-ssh.mydmn.org
L’explication des différentes options est très simple. On trouve en premier lieu la directive de l’utilisateur avec l’option –u permettant de préciser le compte de connexion. On remarquera ici que le second membre après le caractère ‘:’ est laissé à blanc. Il s’agit du mot de passe que la commande nous demandera alors de saisir.
REMARQUE : si l’on souhaite renseigner aussi le mot de passe on devra alors utiliser l’option –u phil:Passw0rd. Bien sûr, cela n’est pas très sécurisé, car le mot de passe apparaîtra lors de la saisie de la commande. Il est donc plus judicieux de laisser le mot de passe à blanc et le saisir à l’exécution de la commande.
Après l’indication du compte de connexion, on trouve respectivement l’option --key pour préciser la clé privée du compte en question, et l’option --pubkey permettant de renseigner la clé publique.
On peut aussi télécharger un fichier depuis un site FTP, en précisant alors le compte et le mot de passe à utiliser :
$ curl ftp://phil:[email protected]:21/file01
Il est possible de décortiquer la commande précédente, en spécifiant le compte de connexion et son mot de passé associé hors de la commande, en exécutant l’instruction ci-dessous (ce qui revient au même que la commande ci-dessus):
$ curl –u phil:Passw0rd ftp://ftp.mydmn.org:21/file01
Parfois, le protocole FTP est sécurisé et l’on doit télécharger des fichiers depuis un serveur FTP SSL. Dans ces conditions, on doit alors exécuter la commande suivante (où Passw0rd est à remplacer par le véritable mot de passe du compte utilisé):
$ curl --ftp-ssl –u phil:Passw0rd ftp://mydmn.org:21/file01
Parmi les nombreuses possibilités de téléchargement offertes par l’outil curl, il existe également un dernier cas de figure nécessitant une connexion par login interposé: le fait de télécharger un fichier d’un site web dont l’authentification de type ‘HTACCESS’ requiert un compte et un mot de passe :
$ curl http://phil:[email protected]/file01
On peut bien évidemment appliquer ce principe aux autres protocoles LDAP, POP, IMAP, etc. Une fonctionnalité que je trouve particulièrement intéressante, c’est qu’il est possible de reprendre un téléchargement interrompu. En effet, si l’on a démarré la récupération d’une image ISO (par exemple), mais que celle-ci s’est brusquement interrompue (ou que l’utilisateur l’a volontairement arrêtée via CTRL+C), on peut reprendre le téléchargement de l’image ISO, en exécutant :
$ curl –C - -O http://ftp.pasteur.fr/mirrors/CentOS/7/isos/x86_64/CentOS-7-x86_64-DVD-1708.iso
REMARQUE : généralement, curl télécharge les fichiers demandés de façon optimum (c’est-à-dire le plus rapidement possible). Mais, dans certains cas, il se peut que l’on soit contraint de limiter la bande passante utilisée, afin de laisser les ressources disponibles pour d’autres connexions ou d’autres applications. Pour se faire, on peut utiliser l’option --limit-rate :
$ curl --limit-rate 5MB –O http://site.mydmn.org/file01
Dans l’exemple précèdent, il ne sera pas possible de télécharger les fichiers à plus 5 Méga bytes par seconde. On peut également faire en sorte de ne télécharger les fichiers que si ceux-ci ont été modifiés avant une date passée en paramètre, grâce à l’option –z :
$ curl –z <JJ-MMM-AA> http://site.mydmn.org/file01
A l’inverse, si l’on souhaite déverser un fichier sur un site FTP (on parle alors d’uploader le fichier), il faut exécuter la commande suivante :
$ curl –u phil:FTPPassw0rd –T file02 ftp://site-ftp.mydmn.org/
La fonction correspondant à l’upload d’un fichier peut s’obtenir en utilisant l’option --upload-file.
IV. Collecteur d'information
Outre ses fonctionnalités de téléchargement ou d’upload, curl fournit également de l’information. En effet, si l’on spécifie l’option –v on peut alors récupérer plus d’information concernant les entêtes HTTP (ou du protocole utilisé), les éventuels cookies, les balises activées… :
$ curl –v http://repo/mirrors.ircam.fr/
Cela devrait alors fournir le résultat ci-dessous (en considérant que l’on dispose bien d’un dépôt à l’adresse http://repo/mirrors.ircam.fr/):
* About to connect() to repo port 80 (#0) * Trying 10.87.1.168... connected * Connected to repo (10.87.1.168) port 80 (#0) > GET /repo/mirrors.ircam.fr/ HTTP/1.1 > User-Agent: curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.19.1 Basic ECC zlib/1.2.3 libidn/1.18 libssh2/1.4.2 > Host: repo > Accept: */* > < HTTP/1.1 200 OK < Date: Wed, 04 Apr 2018 09:09:09 GMT < Server: Apache/2.4.6 (CentOS) < Content-Length: 917 < Content-Type: text/html;charset=ISO-8859-1 < <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN"> <html> <head> <title>Index of /repo/mirrors.ircam.fr</title> </head> <body> <h1>Index of /repo/mirrors.ircam.fr</h1> <table> <tr><th valign="top"><img src="/icons/blank.gif" alt="[ICO]"></th><th><a href="?C=N;O=D">Name</a></th><th><a href="?C=M;O=A">Last modified</a></th><th><a href="?C=S;O=A">Size</a></th><th><a href="?C=D;O=A">Description</a></th></tr> <tr><th colspan="5"><hr></th></tr> <tr><td valign="top"><img src="/icons/back.gif" alt="[PARENTDIR]"></td><td><a href="/repo/">Parent Directory</a> </td><td> </td><td align="right"> - </td><td> </td></tr> <tr><td valign="top"><img src="/icons/folder.gif" alt="[DIR]"></td><td><a href="pub/">pub/</a> </td><td align="right">2017-07-11 09:47 </td><td align="right"> - </td><td> </td></tr> <tr><th colspan="5"><hr></th></tr> </table> </body></html> * Connection #0 to host repo left intact * Closing connection #0
REMARQUE : l’option --trace peut également fournir une image complète des requêtes effectuées.
Maintenant, il ne nous a pas échappé que lors des téléchargements, l’outil curl fournit également des informations liées à la vitesse de transfert, à la réception et à l’émission des paquets :
![]()
Mais, on peut encore aller plus loin en utilisant l’option --trace-ascii afin de rediriger le résultat des requêtes vers un fichier en sortie:
$ curl --trace-ascii myfile.txt http://repo/mirrors.ircam.fr/
On trouvera alors dans le fichier myfile.txt l’intégralité des requêtes exécutées ainsi que la longueur des paquets échangés :
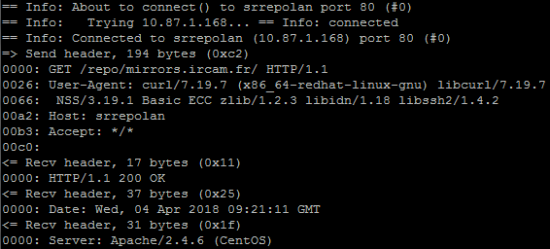
On peut compléter ces informations par la durée des échanges, en ajoutant également l’option --trace-time :
$ curl --trace-asci myfile.txt --trace-time http://repo/mirrors.ircam.fr/
Le résultat sera de la forme suivante et on disposera alors d’une référence temporelle (en plus de la taille des échanges):
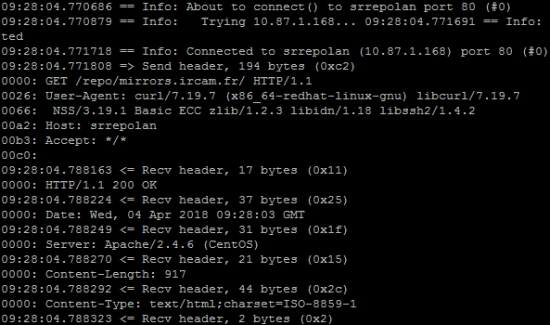
On peut également demander au serveur de fournir l’entête d’identification du protocole concerné. Par exemple, pour une URL, on peut alors exécuter :
$ curl --head http://repo/mirrors.ircam.fr/
REMARQUE : cette option correspond au format court standard à l’option –l et fournit alors l’entête du protocole utilisé.
Exemple: pour le protocole HTTP:

On peut intégrer l’option –i (en version longue il s’agit de l’option --include) qui permet d’afficher les réponses à l’entête précédemment envoyée au client :

V. Fonctionnalités avancées de Curl
Une autre fonctionnalité intéressante de curl est que l’on peut envoyer des messages, puisque l’outil est compatible avec le protocole SMTP. Il est donc envisageable d’exécuter une commande telle que :
$ curl --mail-from [email protected] --mail-rcpt [email protected] smtp://srv-smtp.mydmn.org
Curl demandera alors à saisir le message à envoyer. Notons que l’outil est également compatible avec les protocoles IMAP et POPO3 permettant ainsi de télécharger des messages, au lieu de les envoyer. L’outil curl permet aussi de fixer un serveur proxy par lequel obligatoirement passer pour tout chargement. L’option à utiliser est –x :
$ curl –x proxy.mydmn.org:3128 http://www.mydmn.org/
REMARQUE : le port TCP/3128 correspond au port d’échange du proxy server Squid. Mais, on peut utiliser n’importe quel autre type de serveur proxy.
ATTENTION : si jamais des variables concernant un éventuel proxy (telles que http_proxy, https_proxy ou ftp_proxy) ont été positionnées, il est fortement conseillé de les invalider à l’aide des commandes ci-dessous, car elles peuvent entrer en conflit avec l’utilisation faite via curl :
$ unset http_proxy $ unset https_proxy
Par ailleurs, comme curl est intégralement adapté au protocole HTTP, il est possible de simuler en une seule requête à la fois l’envoi d’une entête et celui d’un message de type GET :
$ curl –l http://www.mydmn.org/ --next www.mydmn.org/
C’est l’option --next qui se charge de séparer les deux types de requêtes. Cela vaut aussi pour séparer un envoi de type POST et celui d’un GET.
Exemple: pour envoyer une requête curl avec un message POST suivi d’un GET :
$ curl -d user=phil http://www.mydmn.org/post.cgi --next http://www.mydmn.org/page.html
On voit ainsi toutes les possibilités offertes par ce genre de mécanisme. Il devient alors possible de tester non seulement les fonctions GET du protocole HTTP, mais également les fonctions PUT, POST et DELETE.
En introduction, il a été question des cookies. En effet, les navigateurs web effectuent leur vérification côté client au travers d’un système de jetons appelés cookies et contenant des indications de contenu. Ces jetons sont émis au client par le serveur en lui indiquant sur quel chemin et quelle machine (nom précis), il souhaite voir le cookie être retourné. Généralement, ce jeton dispose aussi d’une date de péremption et de quelques autres propriétés. Le client en retour, renvoie le cookie et son contenu au serveur, à la fin de sa période de validité.
De nombreuses applications utilisent ce genre de mécanisme permettant d’émettre une série de requêtes via une simple session logique. Pour rester cohérent avec ce genre d’échange, curl dispose alors de fonctions permettant d’enregistrer et de retourner les cookies, de la façon que les applications web le souhaitent (la même d’ailleurs que celle des navigateurs web décrite ci-dessus). Pour envoyer des cookies en ligne de commande on utilise alors l’option --cookies suivi d’un nom :
$ curl --cookie "name=phil" http://www.mydmn.org
Les cookies sont généralement émis sous forme d’entête HTTP. Il peut alors s’avérer plus rapide d’enregistrer directement l’entête transmis :
$ curl --dump-header HandC.txt http://www.mydmn.org
Au final, on disposera alors de l’entête enregistré sous forme de cookies dans le fichier HandC.txt. On peut également souhaiter utiliser un cookie précédemment enregistré dans un fichier. Pour se faire, on exécutera l’instruction suivante (où HandC.txt correspond au fichier contenant le cookie enregistré) :
$ curl --cookie HandC.txt http://www.mydmn.org
REMARQUE : Lorsque l’on souhaite uniquement interpréter la signification du cookie, sans autre spécification, on peut alors mentionner un nom de fichier inexistant (dans l’exemple unknown.txt). On rappelle aussi que pour suivre une localisation de ressource le protocole HTTP utilise l’option --location :
$ curl --cookie unknown.txt --location http://www.mydmn.org
VI. Curl et la sécurité
On terminera ce vaste tour d’horizon de la commande curl par un aperçu des possibilités en termes de sécurité. En effet, il existe quelques recettes pour réaliser des échanges ‘HTTP’ sécurisés. Le plus évident reste de très loin le protocole HTTPS (c’est-à-dire HTTP sur SSL), consistant à chiffrer les données envoyées et reçues sur le réseau. Ainsi, les attaquants potentiels auront beaucoup plus de mal à espionner les informations sensibles par ce biais. On peut donc appeler une URL sécurisée via l’outil curl :
$ curl https://www.mydmn.org
Ensuite, dans le monde du protocole HTTPS, on utilise généralement des certificats permettant d’assurer que l’on est bien qui on prétend être (en plus des connexions de type login/password). L’outil curl supporte des certificats de type client, où il est nécessaire de saisir sa passphrase pour que celui-ci soit validé et utilisable ensuite.
REMARQUE : comme pour les mots de passe vus précédemment, on peut saisir la passphrase via la ligne de commande ou sinon de façon interactive lorsque curl la demande.
La syntaxe standard de validation d’un certificat HTTPS est la suivante :
$ curl --cert mycert.pem https://www.mydmn.org
IMPORTANT : de façon réciproque, il est possible de vérifier que le serveur est bien celui qu’il prétend être en s’assurant que le certificat de celui-ci correspond au certificat de l’autorité de certification stocké localement. Si cette vérification échoue, curl refusera l’accès à la connexion. Il est toutefois possible de contourner ce genre de refus via l’option --insecure (ou option –k) afin de forcer l’accès.
Dans le cas où l’on dispose de sa propre autorité de certification, il est possible de préciser à curl d’effectuer la vérification mentionnée ci-dessus en fournissant le certificat CA :
$ curl --cacert ca.pem https://www.mydmn.org/
VII. Conclusion
Au travers de ce tutoriel, on a pu voir l’étendue des possibilités de l’outil curl fournissant des moyens tels que :
- téléchargement
- dépôt
- traces et vérification
- sécurité
Et ce, concernant les nombreux protocoles d’échanges web, messagerie, transfert de fichiers, etc. Même si l’on a vu qu’un certain nombre d’options, bien d’autres existent encore. Notamment, en matière de sécurité, on peut faire appel à des fonctionnalités permettant des accès internet via SOCKS, autorisant alors l’utilisation de curl au travers de navigateur anonymisé tel que tor.
Pour conclure, lorsque l’on souhaite télécharger simplement quelque chose rapidement, sans se préoccuper des indicateurs, on peut se passer de curl et n’utiliser que wget, équivalent basic de curl. Par contre, pour toute opération plus complexe, il est préférable d’utiliser curl et ses nombreuses fonctionnalités.