

Détails des durcissements des sysctl sous Linux : sysctl système
Sommaire
- I. Présentation
- II. Comment modifier un sysctl
- III. Durcissement des sysctl système Linux
- A. Désactivation des SysReq
- B. Interdire les core dump des exécutables setuid
- C. Déréférencement des liens de fichiers
- D. Activation de l’ ASLR
- E. Mappage de la mémoire des adresses basses
- F. Espace de choix plus grand pour les valeurs de PID
- G. Obfuscation des adresses mémoires kernel
- H. Restriction d’accès au buffer dmesg
- I. Restreindre l’utilisation du sous-système perf
I. Présentation
Nous allons dans cet article nous intéresser aux durcissements du noyau proposés par le guide de configuration de l'ANSSI à travers les sysctl. Les guides de bonnes pratiques et de configuration de l'ANSSI sont pour la plupart très pertinents, mais il arrive qu'ils manquent de détails et que la cohérence de certains durcissements puisse être difficile à appréhender. Je vais donc ici m'efforcer de décortiquer les recommandations 22 et 23 du Guide Recommandation de configuration d'un système GNU/Linux de l'ANSSI qui portent sur les paramétrages des sysctl réseau et système en vue du durcissement d'un noyau Linux. Nous parlerons dans cet article des sysctl système et un prochain article portera sur les sysctl réseau.
J'essaierai notamment de mettre en avant les implications en termes de sécurité et les attaques qu'un durcissement permet d'éviter, sans oublier les potentiels effets de bords si ceux-ci sont connus et les éventuelles questions qui restent en suspens après avoir tenté de creuser ce sujet.
Pour les systèmes utilisant systemd, la configuration des sysctl se trouve dans /etc/sysctl.d/.conf, /usr/lib/sysctl.d/.conf. et /etc/sysctl.conf.
Attention, depuis récemment (2017) il se peut que certains systèmes utilisant systemd n'appliquent plus les configurations sysctl indiquées dans /etc/sysctl.conf. Seuls les fichiers ayant une extensions .conf et situés dans les répertoires /etc/sysctl.d ou /usr/lib/sysctl.d sont appliqués.
➡ A lire également : Détails des durcissements des sysctl sous Linux : sysctl réseau
II. Comment modifier un sysctl
Il existe deux possibilités de modification d'un sysctl, soit de façon temporaire, c'est à dire valable jusqu'au prochain redémarrage, soit de façon persistante, c'est à dire qui persiste après un redémarrage.
Pour modifier une configuration sysctl de façon temporaire, on peut modifier à chaud la valeur stockée dans le fichier correspondant au sysctl à modifier, par exemple :
# echo 1 > /proc/sys/kernel/sysrq
Ou utiliser la commande sysctl pour faire cette même opération :
# sysctl -w kernel.sysrq=1
Pour modifier un sysctl de façon persistante, il faut aller modifier le fichier configuration (/etc/sysctl.d/99-sysctl.conf, ou autre fichier finissant par .conf dans le même dossier) et y modifier ou ajouter notre valeur pour le sysctl souhaité :
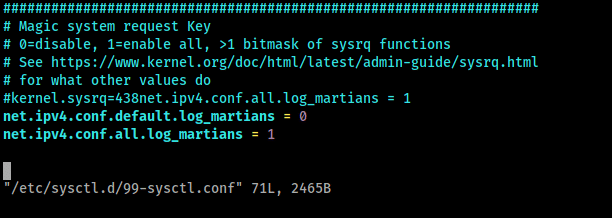
Pour être techniquement plus précis, une configuration modifiant un sysctl est appelée clé. Ici la clé est donc net.ipv4.conf.default.log_martians et 0 est la valeur associée à cette clé.
Pour afficher l'ensemble des sysctl actuellement utilisées et appliquées, la commande suivante est à utiliser :
# sysctl -a
Enfin pour récupérer un sysctl précis, la commande suivante est à utiliser :
# sysctl -n net.ipv4.conf.eth1.log_martians
III. Durcissement des sysctl système Linux
A. Désactivation des SysReq
Les SysReq ou Magic System Request Key sont une fonctionnalité du noyau Linux permettant, via une combinaison de touche réalisable à tout moment, de lancer des commandes bas niveau, par exemple afin de pouvoir redémarrer un système bloqué sans corrompre le système de fichiers ou tuer un programme paralysant les ressources du système. Parmi les actions réalisables :
- Déterminer le niveau de log de la console
- Redémarrer l'ordinateur reBoot
- Redémarrer via kexec pour faire un crashdump Crashdump
- Envoyer un signal de terminaison (SIGTERM) à tous les processus (sauf init) tErm
- Tuer le processus qui consomme le plus de mémoire (via oom-killer)
- Envoyer un signal de fin (SIGKILL, plus ferme que SIGTERM) à tous les processus (sauf init)
- Tuer tous les processus de la console virtuelle courante.
- Envoyer un signal de fin (SIGKILL, plus ferme que SIGTERM) à tous les processus (même init)
- Afficher le contenu actuel de la mémoire Memory
- Éteindre le systeme via APM Out
- Afficher sur la console les registres et drapeaux actuels Print
- Basculer la gestion du clavier de mode brute (raw) à XLATE
- Synchroniser les disques (tente d'écrire toutes les données non sauvegardées)
- Afficher une liste des taches et autres informations dans la console
- Remonter les disques en lecture seule
À noter que même si les SysReq sont activées, une partie seulement de ces actions sont réalisables dans la configuration par défaut. D'autres requièrent une configuration spécifique. Cette combinaison de touche clavier doit être réalisée sur un terminal "physique", entendez par là qu'une connexion SSH ne sera pas suffisante, en théorie :).
Il existe en effet une petite astuce permettant d'exécuter des SysReq depuis une connexion distante, et cela en utilisant directement une fonctionnalité "native" de sysctl, le fichier /proc/sysrq-trigger. Si l'on souhaite redémarrer le système par exemple, il faut envoyer l'instruction "b", et donc :
echo "b" > /proc/sysrq-trigger
Ce fichier n'est cependant modifiable que par l'utilisateur root :
user91@kali:~$ ls -al /proc/sysrq-trigger --w------- 1 root root 0 juil. 28 2018 /proc/sysrq-trigger
Pour gérer cela, il faut se rendre dans le fichier /proc/sys/kernel/sysrq ou utiliser la clé kernel.sysrq dans un fichier de configuration sysctl.
Positionner la valeur 1 permet d'activer l'utilisation des SysReq (valeur par défaut sur une majorité de systèmes), positionner la valeur 0 interdit toute utilisation des SysReq. Lorsque la valeur est autre que 0 ou 1, c'est que certaines commandes sont autorisées, d'autres non, à utiliser en connaissance de cause donc. À nouveau, comme cette fonctionnalité est très rarement utilisée, voir inconnue des sysadmins la plupart du temps, mieux vaut la désactiver :
kernel . sysrq = 0
L'ANSSI recommande en effet de positionner la valeur de cette clé à 0 afin de désactiver totalement leur utilisation. On peut imaginer les effets de bords possibles grâce à ces commandes, notamment en ce qui concerne la possibilité de tuer des processus, afficher les registres CPU, démonter un système de fichier, redémarrer la machine, etc. À noter que le plus grand danger reste l'exploitation de ces SysReq à partir d'un terminal physique par un utilisateur non privilégié, mais leur utilisation n'est pas forcément restreinte au terminal physique comme je l'ai indiqué précédemment.
La frontière entre physique et virtuel s'étant quelque peu estompée ces dernières années, j'ignore par exemple si l'on peut lancer des SysReq à partir d'un clavier virtuel, dans le cas d'un accès distant VNC, via une console d'hyperviseur type VMWare/Proxmox, etc.
B. Interdire les core dump des exécutables setuid
Par défaut, le système va réaliser un core dump (extraction de la mémoire) des processus s'arrêtant brusquement, cela est notamment pratique pour du debug, avoir une photo à l'instant du crash permet de voir quelles données ou actions ont potentiellement causé ce crash.
Cependant, ces dumps sont exécutés par le kernel et écrits sur le système avec les droits de l'utilisateur courant (celui ayant lancé la commande). Dans le cadre de l'utilisation d'un exécutable setuid ou setgid, l'extraction mémoire contiendra les informations d'un programme exécuté avec les droits d'un autre utilisateur, probablement avec un plus haut niveau de privilège que l'utilisateur courant ou root, mais sera écrit sur le système avec les droits de l'utilisateur courant (non privilégié). Ainsi, des informations sensibles, permettant potentiellement une élévation de privilège, pourront se trouver dans ce type de fichier et lisible par l'utilisateur courant.
Afin de contrôler ce comportement, on peut utiliser la clé fs.suid_dumpable afin de ne pas produire de core dump pour les exécutables possédant un bit setuid ou setgid.
fs.suid_dumpable = 0
L'ANSSI recommande de passer la valeur de la clé fs.suid_dumpable à 0 pour désactiver tout core dump sur les exécutables possédant un bit setuid ou setgid, et ainsi éviter d'éventuelles fuites de données sensibles concernant les attributs, les fichiers accédés ou d'autres actions d'un utilisateur privilégié.
C. Déréférencement des liens de fichiers
Une des vulnérabilités courantes sous Linux concernant les liens symboliques est le symlink-based time-of-check-time-of-use race (ou symlink race condition). Il s'agit d'un delta de temps entre le moment où un fichier est contrôlé (pour voir si les droits d'accès sont suffisants) et celui où il est utilisé par un programme.
Pendant le laps de temps où ces deux opérations sont effectuées, un utilisateur malveillant peut créer un lien symbolique portant le nom de ce fichier et ainsi manipuler une partie de l'exécution du programme, qui s'exécute idéalement avec un plus haut niveau de privilège. Un exemple courant fourni comme explication est le suivant :
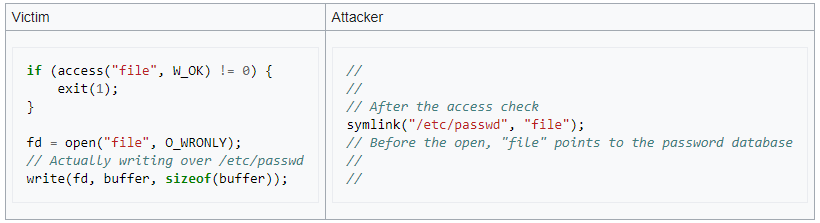
Dans cet exemple, le programme contrôle les permissions d'un fichier file avec l'instruction access() en C. Puis, dans un deuxième temps si les permissions le permettent, il va écrire dans ce fichier. Dans le cadre d'une attaque, l'attaquant va laisser le fichier tel quel pour la première opération (par exemple créer lui-même le fichier file en permission 777 pour que le programme constate qu'il peut y écrire). Puis, il va remplacer ce fichier par un lien symbolique pointant vers /etc/passwd. Le programme s'exécutant avec un haut niveau de privilège va alors exécuter sa deuxième instruction et écrire dans le fichier file, qui sera en réalité/etc/passwd.
Un très bon labo est mis à disposition sur ce Gitlab Ranjelikasah/ace-Condition-Seedsecurity, je vous le recommande si vous souhaitez expérimenter par vous-même 🙂
Ce type d'attaque est notamment dangereuse sur les setuid/setgid, qui permettent d'exécuter un binaire avec les droits root (ou d'un autre utilisateur en fonction de leur configuration). C'est pourquoi il est recommandé de durcir ces sysctl qui ont plusieurs effets concernant les liens symboliques et les setuid.
Concernant les hardlinks et pour un utilisateur système créant un lien, l'une des conditions suivantes doit être remplie :
- l'utilisateur peut seulement créer des liens vers des fichiers dont il est le propriétaire
- l'utilisateur doit avoir les droits d'écriture et de lecture vers le fichier vers lequel souhaite créer un lien.
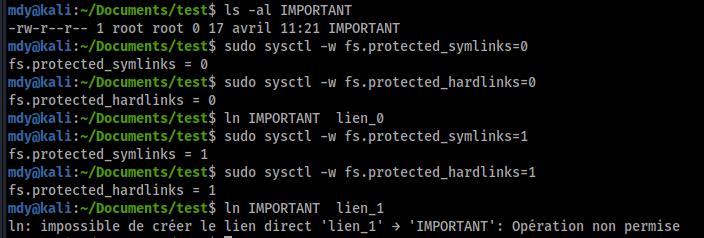
Concernant les symlinks et les processus qui sont amenés à suivre des liens symboliques vers des répertoires world-writable qui ont le sticky bit activé :
- le processus suivant le lien symbolique doit être le propriétaire du lien symbolique
- le propriétaire du répertoire est également le propriétaire du lien symbolique.
Si vous avez bien compris le fonctionnement de l'attaque présentée, vous comprendrez rapidement quelle devient impossible si ces conditions sont imposées via le durcissement sysctl :
fs.protected_symlinks = 1 fs.protected_hardlinks = 1
Ce paramétrage permet en somme de durcir les conditions d'utilisation des symlinks et des hardlinks afin de se protéger des différentes attaques permettant une élévation de privilège
D. Activation de l’ ASLR
L'ASLR (Address Space Layout Randomization) est un mécanisme permettant de limiter les effets et de complexifier l'exploitation des attaques de type buffer overflow (dépassement de tampon). L'objectif est ici de placer la zone de données dans la mémoire virtuelle de façon aléatoire, changeant ainsi sa position à chaque exécution.
L'exploitation de buffer overflow consiste notamment à contrôler une partie des registres CPU afin de modifier le flux d'exécution d'un programme. Cela passe, entre autres, par le contrôle du registre EIP (Extended Instruction Pointer) qui permet d'indiquer à quel offset (adresse mémoire) la prochaine instruction à exécuter se trouve. En contrôlant le registre EIP, l'attaquant peut indiquer au programme de sauter à un offset précis et dont le contenu est sous son contrôle, notamment s'il a réussi à injecter du code malveillant (shellcode) à cet endroit de la mémoire. En modifiant la répartition et le positionnement des instructions, de la pile (stack), du tas (heap) et autres, en mémoire, l'attaquant n'est plus en capacité de pointer vers son shellcode car celui-ci ne sera jamais au même endroit à chaque exécution.
Pour activer l'ASLR, on peut utiliser la clé kernel.randomize_va_space et y positionner la valeur 2, qui permet de positionner de façon aléatoire (aka randomiser :/ ) la stack (pile), les pages CDSO (virtual dynamic shared object), la mémoire partagée et le segment de données (data segment), qui contient les variables globales et statiques initialisées par le programme. Positionner la valeur 1 aura le même effet, sauf pour le segment de données. La valeur 0 désactive l'ASLR.
kernel.randomize_va_space = 2
Pour plus d'information sur les buffer overflow, je vous oriente vers les très bons articles (en français) d'0x0ff :
E. Mappage de la mémoire des adresses basses
Une vulnérabilité de type NULL pointer dereference est le fait pour un programme d'utiliser un pointeur non initialisé (valant NULL) ou pointant vers une adresse mémoire inexistante (0x00000000). De fait, lorsque ce programme utilisera ce pointeur dans ses instructions, cela causera un crash. Dans le contexte d'exécution du noyau ou d'un programme à haut niveau de privilège, le fait de déclencher intentionnellement l'utilisation d'un pointeur NULL par un attaquant lui permet de faire crasher le programme, voir le système.
Cependant, si l'attaquant parvient à identifier l'adresse mémoire du pointeur en question et à la manipuler pour y insérer les données de son choix avant qu'elle ne soit utilisée activement par le noyau ou un programme à haut niveau de privilège, alors il pourra contrôler son utilisation dans le programme exécuté, menant à une potentielle élévation de privilège.
En C, un pointeur est une variable qui permet de stocker non pas une valeur ("ABC" ou 12,28), mais une adresse mémoire. Lorsqu'un programme démarre, le système lui alloue une zone mémoire dans laquelle il peut s'organiser. Cette zone mémoire est constituée de "cases" de 8 bits (octets). Chacune de ces cases (appelées blocs) est identifiée par un numéro : son adresse. On peut alors accéder à une variable soit par son nom "agePersonne", soit par l'adresse du premier bloc alloué à la variable en question, c'est-à-dire son pointeur.
Il se trouve que le noyau a tendance à plutôt utiliser les adresses mémoires dites "basses", si l'attaquant parvient à manipuler les pointeurs visant des blocs d'adresses mémoires "basses", alors il a plus de chances de trouver un bloc d'adresse qui sera ensuite utilisé par le noyau.
La clé vm.mmap_min_addr est donc une constante qui permet d'empêcher les utilisateurs non privilégiés de créer des mapping mémoires en dessous de cette adresse. Elle permet de définir l'adresse minimale qu'un processus n'ayant pas les droits root peut mapper, adresse que nous allons rehausser par rapport à sa valeur par défaut (0) :
vm.mmap_min_addr = 65536
Attention toutefois à bien tester le fonctionnement de vos programmes et applications avec ce paramètre avant de passer en production.
F. Espace de choix plus grand pour les valeurs de PID
Sous Linux (et Windows), le PID (Process IDentifier) est un numéro unique assigné à un processus en cours d'exécution. Il permet son identification parmi d'autres processus pour leur gestion, par exemple lorsque l'on utilise les commandes ps ou kill.
Comme pour les ports clients, les PID sont en nombre limité sur un système. Il se peut donc que toute la plage de PID disponible soit saturée par un dysfonctionnement ou une attaque. Dès lors, aucun autre processus ne pourra être créé, car il n'aura aucun PID à utiliser. L'ANSSI recommande d'élargir la plage du nombre de PID disponible sur un système afin d'éviter ou de limiter de tels scénarios :
kernel.pid_max = 65536
Cette configuration permet donc de prévenir d'une saturation de PID entrainant une impossibilité de créer de nouveau processus. Sur les systèmes 32 bits, la valeur max est de 32 768 alors que pour les systèmes 64 bits, elle est de 2^22 (4 194 304, ça fait beaucoup de processus). À noter toutefois que les PID sont "recyclés", c'est-à-dire que lorsqu'un processus avec un certain PID se termine, ce PID peut être réutilisé plus tard par un autre processus. Ce durcissement vise donc à élargir le nombre de processus tournant simultanément sur votre système, ce qui ne sera le cas qu'en cas d'attaque ou pour des serveurs à très haute performance.
G. Obfuscation des adresses mémoires kernel
Un attaquant qui cherche à compromettre un noyau en cours d'exécution en écrasant les structures de données du noyau ou en forçant un jump (saut) vers un code de noyau spécifique doit, dans les deux cas, avoir une idée de l'emplacement des objets cibles en mémoire. Des techniques comme l'ASLR ont été créées dans l'espoir de "dissimuler" cette information, mais cet effort est vain si le noyau divulgue des informations sur l'endroit où il a été placé en mémoire. Il existe en effet plusieurs cas de figure où des adresses mémoires relatives au kernel peuvent être affichées (fuitées) vers l'espace utilisateur, qui obtient alors des informations intéressantes sur les pointeurs à cibler dans le cadre d'une attaque.
L'ANSSI recommande de paramétrer la directive suivante à 1 afin que, dans certains cas, les adresses mémoires relatives au noyau affichées par un programme soit dissimulées (remplacées par des 0) :
kernel.kptr_restrict = 1
Attention toutefois, cette dissimulation n'est effective uniquement si le programme utilise la notation %pK (au lieu de %p pour un pointeur "normal"). C'est-à-dire que le développeur a marqué le pointeur vers une adresse noyau comme tel et indique donc au système que l'information doit être protégée. Dans le cas où un programme ne respecte pas cette bonne pratique, le durcissement au niveau du sysctl est inutile.
Enfin, si l'utilisateur possède la capabilities CAP_SYSLOG dans le contexte d'exécution du programme, les adresses mémoire kernel seront affichées normalement (paramétrez la sysctl à 2 si vous souhaitez éviter ce cas de figure).
H. Restriction d’accès au buffer dmesg
Sous Linux, la commande dmesg permet de voir les journaux (plus précisément la mémoire tampon des messages) relatifs au kernel, par exemple ceux créés par les drivers, lors du démarrage du système ou au branchement d'un nouveau périphérique. Ces messages sont ensuite stockés dans le fichier /var/log/messages.
L'ANSSI recommande de configurer le sysctl suivant à 1 afin de n'autoriser que les utilisateurs privilégiés à consulter ce type d'information via la commande dmesg :
kernel.dmesg_restrict = 1
L'objectif est ici de dissimuler les informations relatives aux journaux du noyau de la vue des utilisateurs, ceux-ci peuvent en effet dans certains cas contenir des informations sensibles pouvant être utilisées dans le cadre de futures attaques.
Voici un exemple de l'utilisation de la commande dmesg par un utilisateur non privilégié avec le paramétrage à 1, puis à 0 :
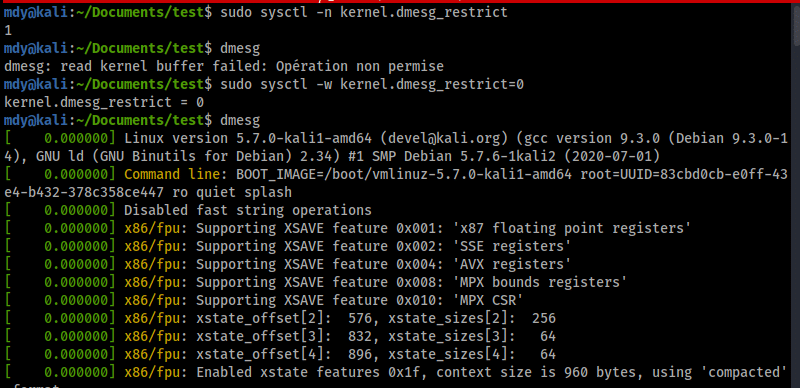
I. Restreindre l’utilisation du sous-système perf
Sous Linux, le sous-système perf est une commande très complète et puissante qui permet de mesurer les performances d'un programme ou du système. Il réalise ces mesures en étant au plus proche de l'hardware, ce qui nécessite un niveau de privilège élevé.
L'ANSSI recommande le paramétrage à 2 de la sysctl suivante afin de limiter l'accès des utilisateurs non privilégiés à cette commande :
kernel.perf_event_paranoid = 2
Ainsi, un utilisateur non privilégié ne sera pas en mesure d'utiliser cette commande, qui peut notamment impacter les performances du système. Ce paramétrage est effectif sauf si l'utilisateur en question possède la capabilities CAP_SYS_ADMIN.
Également, les deux sysctl suivantes doivent être paramétrées à 1 :
kernel.perf_event_max_sample_rate = 1 kernel.perf_cpu_time_max_percent = 1
Ces deux sysctl servent à gérer combien de ressource et de temps CPU le système de performance peut utiliser. Il s'agit d'un pourcentage (1% du temps CPU). Ces configurations visent à limiter l'impact du sous-système perf sur le système lors de son utilisation. Attention, mettre ces deux sysctl à 0 fait tout simplement sauter toute limite, ce qui serait contre-productif 🙂
Quoi qu'il en soit l'idée derrière le paramétrage de ces deux sysctl est de limiter l'impact du sous-système perf. sur les performances du système.
Rendez-vous dans le prochain article pour l'étude des durcissement des sysctl réseau :). N'hésitez pas à signaler toute erreur ou précision technique dans les commentaires 🙂











Merci pour cet excellent article bien documenté
Oui merci beaucoup