

Comment maîtriser la recherche sous Linux ?
Sommaire
I. Présentation
Comme vous le savez tous, le système d’exploitation Linux est organisé en arborescence avec pour point d’entrée la racine, notée ‘/’. Mais, comme tout est fichier, cela représente alors des centaines de milliers de documents. Que faire lorsqu’on recherche un fichier en particulier et que l’on n’en connaît pas forcément le nom, mais uniquement certains critères. Dans ce tutoriel je vous propose d’explorer les différentes techniques et commandes de recherche des fichiers et des bibliothèques Nous explorerons les trois possibilités principales que sont :
- locate (et ses dérivés : mlocate ou slocate)
- find
- grep (recherche de contenu)
REMARQUE : durant ce tutoriel on expliquera également comment utiliser la fonction xargs afin de construire et d’exécuter certaines commandes complexes sur l’ensemble des fichiers recherchés (et trouvés, au final).
II. La commande locate
Le programme locate réalise une recherche rapide et indexée au sein d’une base interne de chemins d’accès et renvoie comme résultat tout nom correspondant à une chaîne de caractères de recherche.
Exemple : recherche des commandes commençant par ‘if’ :
$ locate bin/if
Le résultat renvoyé devrait être (du moins sur une distribution GNU/Linux CentOS7), quelque chose comme l’écran suivant :

Il est également possible de combiner la commande de recherche locate avec un filtrage sur le nom du répertoire parent :
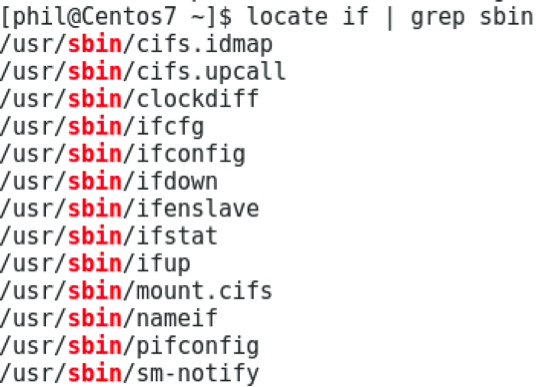
Le programme locate existe depuis de nombreuses années et possède différentes variantes dans les cas d’usage standard. Sur les plateformes Linux des distributions modernes communes, on peut trouver les deux programmes suivants, accessibles par des liens symboliques nommés locate:
- slocate
- mlocate
Afin de visualiser la version et la précision du type de commande de recherche dont on dispose on peut utiliser la commande locate –V :

Dans certains cas, juste après une installation du système la commande locate échoue. Mais, lorsqu’on l’on essai à nouveau 24h plus tard, la commande recherche correctement les fichiers demandés, selon les critères positionnés, sans que l’on ait effectué une quelconque correction. Que s’est-il passé entre temps ?
En fait, la commande locate recherche depuis une base interne, créée (ou remise à jour), par le programme updatedb. Ce dernier s’exécute automatiquement, via une tâche planifiée cron. Or, sur beaucoup de système, cette trâche ne s’exécute qu’une fois par jour, à heure fixe. Aussi, il se peut que nous ne nous trouvions tout simplement pas dans le créneau horaire de l’exécution de cette tâche planifiée de mise à jour et/ou de création de la base interne de recherche locate, au moment de l’installation du système. Dans ce cas, il ne faut pas hésiter à exécuter manuellement la commande updatedb.
La version slocate est une version sécurisée de la commande locate GNU, fonctionnant dans les environnements SELinux. Cela permet de fournir une méthode sécurisée d’indexation et de recherche rapide des fichiers du système d’exploitation, dans ce genre d’environnement hautement cloisonné. Pour cela on utilise un encodage incrémental telle que la commande locate GNU, permettant de compacter la base de données interne et accélérer ainsi les recherches, tout en stockant les permissions ainsi que la propriété des fichiers. Cela permet aux utilisateurs de ne pas voir les fichiers auxquels ils ne devraient pas avoir accès.
Afin de créer une nouvelle base de données, avec la commande locate (ou mlocate), à partir de la racine, on peut exécuter l’instruction suivante :
$ locate –u
Si par contre, on souhaite créer une base de recherche à partir d’un répertoire autre que la racine, il faut alors exécuter la commande suivante :
$ locate –U <Directory>
Afin d’exclure des répertoires complets de la recherche des chemins de la base locate, il suffit d’exécuter l’ordre suivant :
$ locate –e <Directory1, Directory2,…>
On peut également analyser la cohérence de la base interne ainsi créée, en utilisant l’option –c. Par défaut, cette commande permet d’analyser le fichier /etc/updatedb.conf :
$ locate –c
ATTENTION : par défaut, la commande locate possède un niveau de sécurisation. Si l’on souhaite accélérer les recherches, on peut désactiver cette fonctionnalité de sécurité en exécutant :
$ locate –l 0
Pour revenir au mode sécurisé, il suffit simplement d’exécuter la commande suivante :
$ locate –l 1
Lors d’une recherche, on peut éliminer les messages en sortie et passer à un mode silencieux en utilisant l’option –q. De même, on peut également limiter le nombre de lignes retenues, en utilisant l’option –n suivie du nombre entier de limitation. Afin de lancer une recherche insensible à la casse, on peut aussi utiliser l’option –i. Lorsque l’on souhaite spécifier un chemin différent de la base interne par défaut, on doit utiliser l’option –o suivi du chemin complet et du nom du fichier à créer. Par ailleurs, on peut aussi préciser un ou plusieurs fichiers de base à utiliser lors des recherches, en le mentionnant par l’option –d et en précisant le(s) chemin(s) à utiliser.
REMARQUE : les options décrites ci-dessus, sont bien évidemment valides également pour la commande slocate.
III. La commande find
Là où le programme locate recherche des fichiers avec leur nom, la commande find permet de rechercher avec un nom de répertoire (ainsi que ses sous-répertoires) selon différents critères et attributs des fichiers. Dans sa version basique, la commande permet de recherche sur un ou plusieurs répertoires de l’arborescence.
Exemple :recherche dans le répertorie d’accueil /home/phil :
$ find ~
Là où la commande find devient véritablement intéressante, c’est qu’elle permet d’effectuer une recherche par type: fichier simple, répertoire, liens symboliques, etc. :
$ find ~ -type d
De façon générale, il est alors possible d’interroger cette commande pour les types standard du système :

De la même façon, on peut aussi rechercher des fichiers par taille ou par nom, en utilisant respectivement les indicateurs –size ou –name. Bien évidemment, il est aussi possible de les combiner entre eux, afin de filtrer encore plus précisément ses critères de recherche.
Exemple : recherche des fichiers d’images de taille 1Mio :
$ find ~ -type f –name "*.jpg" –siez +1M
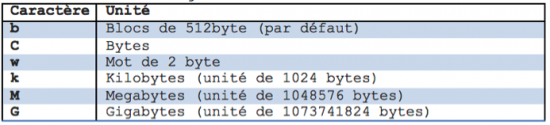
REMARQUE :l’unité ‘M’ mentionnée ici, peut également être exprimée différemment en changeant le caractère de l’unité :
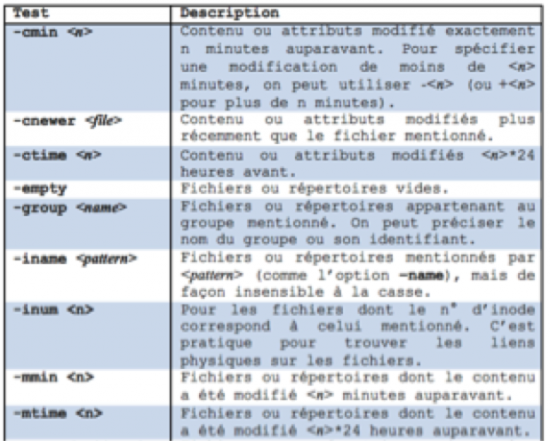
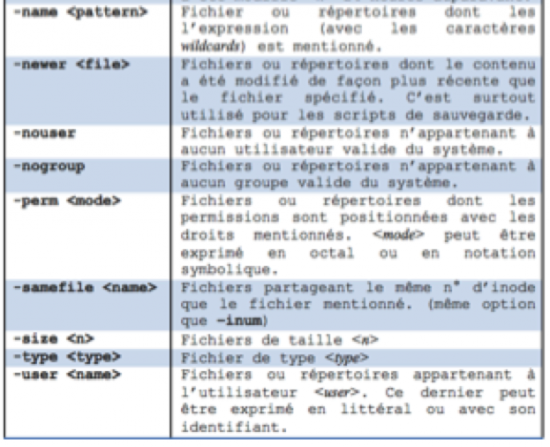
La commande find supporte de nombreux tests. Ci-dessous voici un petit résumé des principaux utilisés :
De plus, on peut combiner ces différents tests au moyen d’opérateurs logiques : -and, -or et –not en les regroupant sous forme de blocs, protégés par des parenthèses :
$ find ~ \( -type f –not –perm 0644 \) –or \( -type d –not –perm 0700 \)
De façon plus générale, lorsque l’on souhaite combiner deux expressions entre elles à l’aide de ces opérateurs, il faut tenir compte du résultat de la première expression pour savoir si oui ou non la seconde sera exécutée :
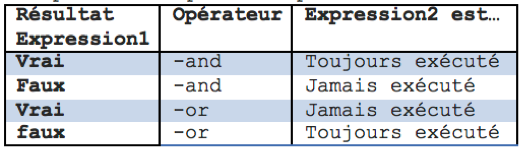
En tenant compte ainsi du tableau ci-dessus, on favorise l’amélioration des performances de l’exécution des conditions de recherche. Pour finir, il existe quatre actions prédéfinies, permettant respectivement de supprimer un fichier, de lister les propriétés des fichiers trouvés, de visualiser le chemin complet des fichiers recherchés, ou d’arrêter la recherche dès qu’un fichier correspond aux critères spécifiés.

ATTENTION : l’utilisation de l’option –delete doit être effectuée avec précaution. Il est conseillé de toujours lister les fichiers recherchés, à l’aide de l’option –print auparavant.
En complément des actions prédéfinies vues ci-dessus, on peut également invoquer des commandes arbitraires en utilisant la directive –exec, suivie de la commande avec les caractères ‘{} ;’ en fin de chaîne.
Exemple: réaliser la même action que la directive –delete :
$ find ~ -exec rm '{}' ' ;'
REMARQUE : à cause de sa signification particulière les accolades et le caractère ‘;’ doivent être mis entre quotes ou échappés.
Afin d’exécuter une action spécifique interactive, on peut utiliser la directive –ok en lieu et place de –exec. Ainsi, il sera demandé à l’utilisateur de répondre avant d’exécuter la commande :
![]()
Exemple : recherche des fichiers de plus de 400Mio depuis la racine :
$ find / -size +400M –exec ls –lh "{}" \ ;
Maintenant que l'on sait rechercher des fichiers, on doit pouvoir combiner la recherche avec l'exécution de commandes sur les fichiers trouvés. La commande find dispose de son propre mécanisme pour exécuter des commandes. Pour se faire, on utiliser args. Ce dernier est très souple et surtout très rapide. Cette commande reçoit sur l’entrée standard (stdin), grâce à un pipe (ou tube), la liste des fichiers trouvés. Puis, on exécute ensuite la commande passée en argument, sur l'ensemble des fichiers reçus au travers de l'interface stdin.
Il est conseillé de s'imposer une bonne pratique d’utilisation en utilisant l’option -print0 et l’argument -0 pour éviter d’avoir des problèmes concernant les espaces ou les caractères spéciaux dans l'expression des chemins. En effet, par défaut, xargs espère disposer de fichiers délimités par des espaces. Donc, dans le cas où un espace existe dans le nom du fichier, cela provoquera des problèmes. Les deux options précédentes, permettent donc de délimiter les noms des fichiers, grâce à un caractère 'NULL'. Cela permet d'éviter les messages d'erreur. L’option -r permet d’éviter d’exécuter la commande passée en argument, même si la liste des fichiers trouvés retourne un ensemble vide.
Exemple : Déplacement des images du répertoire ~/Desktop vers un dossier ~/Pictures :
$ find ~/Desktop \( -iname "*.jpg" -o -iname "*.png" \) -print0 | xargs -0 mv --target-directory ~/Pictures
On peut facilement utiliser cette option pour modifier les propriétés des fichiers récupérés au niveau des droits:
$ find ~ -type f -print0 | xargs -0 chmod -c 0600
En complément de l'ensemble des moyens de recherche listés jusque-là, cette dernière possibilité ouvre de nombreuses perspectives et facilite grandement les recherches complexes, tout en unissant la modification des fichiers listés, d'autant que l'on peut également rechercher au sein même des fichiers eux-mêmes.
IV. Recherche dans le contenu des fichiers
Parfois, on peut également avoir besoin de rechercher non pas par rapport à un critère externe des fichiers, mais par rapport au contenu. Pour se faire, on peut alors utiliser la commande grep. IL est alors possible de rechercher une chaine de caractère au sein d’une arborescence :
$ grep "chaine" *
Bien évidemment, il est possible d’effectuer cette recherche de façon récursive en parcourant l’ensemble des sous-répertoires de l’arborescence dans la quelle on se trouve :
$ grep –r "chaine" *
De plus, si l’on ne connaît pas exactement la chaine recherchée, on peut également effectuer une recherche en précisant de ne pas tenir compte de la casse (majuscules/minuscules) :
$ grep –i "chaine" *
Le potentiel de cette simple commande associé à la puissance de recherche de la commande find peut alors autoriser des recherches dans le répertoire spécifié des fichiers de type standard contenant une chaîne de caractères :
$ find <Directory> -type f –print | grep –ri "chaine"
V. Conclusion
On a ainsi parcouru les trois types de recherche de fichiers au sein de l’arborescence du système d’exploitation Linux. On peut dans un premier temps rechercher de façon rapide et indexée via la base interne de la fonction locate, ou encore effectuer la recherche manuellement via la commande find. Pour finir, si l’on dispose de critères de contenu, il est possible de rechercher aussi via la commande grep tout en combinant ces commandes pour une plus grande étendue de la plage de recherche. J’espère que cela vous permettra de ne plus être perdu et de retrouver rapidement vos données au sein de vos serveurs. A l’ère du big data il est essentiel de savoir se repérer rapidement dans la masse d’information mise à disposition.










Et xargs?
Bonsoir
à quoi pensez-vous avec xargs?
Vous en avez parlez au début du tutoriel en disant qu’on se pencherait dessus, mais comme ce n’est pas le cas, il devait se poser la question.
Bonsoir, Vous avez raison. Excellente remarque. J’ai mentionné son utilisation et j’ai carrément oublié d’en parler. Je vais voir ce que je peux faire pour corriger cet oubli et éditer à nouveau l’article dès que possible.
Merci pour votre remarque judicieuse.
Bon week-end.
Bonjour, merci pour ce résumé très pratique. Cependant pour ma part je gaère avec locate, j’ai l’impression qu’il ne permet pas de trouver un fichier dont on ne connaît pas le milieu du nom. Par exemple je sais que mon fichier commence par DA et que c’est une extension R, je fais donc :
locate DA_*.R
ce qui ne me donne rien du tout. alors que j’en ai. J’ai fait un updatedb mais ça ne change rien, ce sont de vieux fichier bien placés dans mes documents.
Je suis déçue car j’utilisais toujours locate je le trouvais bien plus efficace et simple que find, mais il passe à coté de quelque chose là! tu peux peut-etre m’aider là-dessus/confirmer mon interpretation?
Bonsoir,
Je pense que le comportement de locate est légitime.
Pour rappel, cette commande ne sert à rechercher que les binaires ou bibliothèques.
Je ne suis pas sûr que les programmes R soient considérés comme tels.
Par contre, find devrait pouvoir trouver tes fichiers sans problème:
# find / -name « DA_*.R » … ou quelque chose d’approchant dans ce genre là avec peut-être une notion de date en plus.
Bonne soirée
Cordialement
merci pour cette réponse super rapide. J’avais pris l’habitude de Locate et n’avais pas réalisé son objectif originel. Par contre si je fais locate DA_ là il e sort une liste hyper logue, contenant le fameux DA_XXX.R
Je pense que le souci est plus dans le fait de mettre une étoile au milieu du nom, qu’il ne gèrerait pas très bien?
Bonne soirée