Comment installer et configurer Puppet sous Linux ?
Sommaire
I. Présentation
Je vous propose dans ce billet de vous présenter l’outil d’automatisation appelé Puppet. Il s’agit d’un outil de pilotage très pratique, permettant la centralisation et l’automatisation de la gestion des configurations des serveurs administrés. Ce mode de pilotage consiste à enregistrer de manière précise les informations décrivant les logiciels (ou dans le cadre d’une distribution Linux, les ressources telles que les packages, les systèmes de fichiers, les utilisateurs…), ainsi que le matériel d’une infrastructure, tout en les enregistrant de façon détaillée et pouvoir alors les reproduire autant de fois que nécessaire.
L’outil s’articule autour de deux couches, à savoir :
• un langage de configuration décrivant l’aspect des machine.
• une couche d’abstraction permettant à l’administrateur la mise en œuvre de configuration sur les différentes plateformes ou distributions du parc informatique.
L’administrateur peut ainsi coder la configuration de n’importe quel service, sous la forme de règles que Puppet peut alors contrôler et appliquer. Le logiciel est développé en langage Ruby et diffuse sous licence publique. Le grand intérêt de cette solution réside dans son support multi-plateformes (grâce au langage Ruby) et sa sécurité (basée sur la couche Transport Layer Security ou TLS et une mini PKI ou Public Key Infrastructure).
Par ailleurs, de nombreux développeurs ont partagé leurs codes sous forme de modules Puppet, au sein d’une forge, dont le développement reste ainsi très actif et favorise une mise en œuvre de la solution grandement facilitée. Le langage déclaratif Ruby est un grand contributeur du déploiement de la solution, car il permet la création et la gestion des modules, utilisant les ressources et les classes au sein de ses manifestes (il s’agit ni plus ni moins d’un synonyme pour le terme module), afin de définir les différents états d’un service ou d’une application.
Les utilisateurs de Puppet apprennent rapidement le fonctionnement de l’outil, car celui-ci reste intuitif et dispose d’un contrôle de code intégré. Il s’appuie sur un modèle client/serveur où les nœuds administrés synchronisent les configurations avec le serveur maître. Puppet se décompose en trois grandes fonctionnalités :
• le nœud maître appelé Puppet master
• les bases de données nécessaires à l’historisation appelé Puppet backend
• le panneau de visualisation central appelé Puppet dashboard
Pour pouvoir installer et utiliser Puppet, il est nécessaire de respecter les quelques prérequis suivants :
• disposer des droits d’administration.
• disposer d’une connexion à Internet opérationnelle et configurée.
• disposer d’un parc de serveurs à administrer (sinon ça n’est pas vraiment utile).
• faire très attention lors des modifications
En effet, une erreur dans la configuration de Puppet peut alors entrainer un blocage de l’ensemble des serveurs concernés et pas uniquement d’un seul serveur. On peut donc considérer un manifeste (aussi appelé module) comme l’empilement des trois couches suivantes :
• le système d’exploitation (au plus bas niveau)
• les applications (au niveau intermédiaire)
• les configurations (au plus haut niveau)
La représentation ci-dessous en découle donc, mettant en évidence la facilité d’utilisation selon les différents types de systèmes d’exploitation, de distributions ou d’équipements :
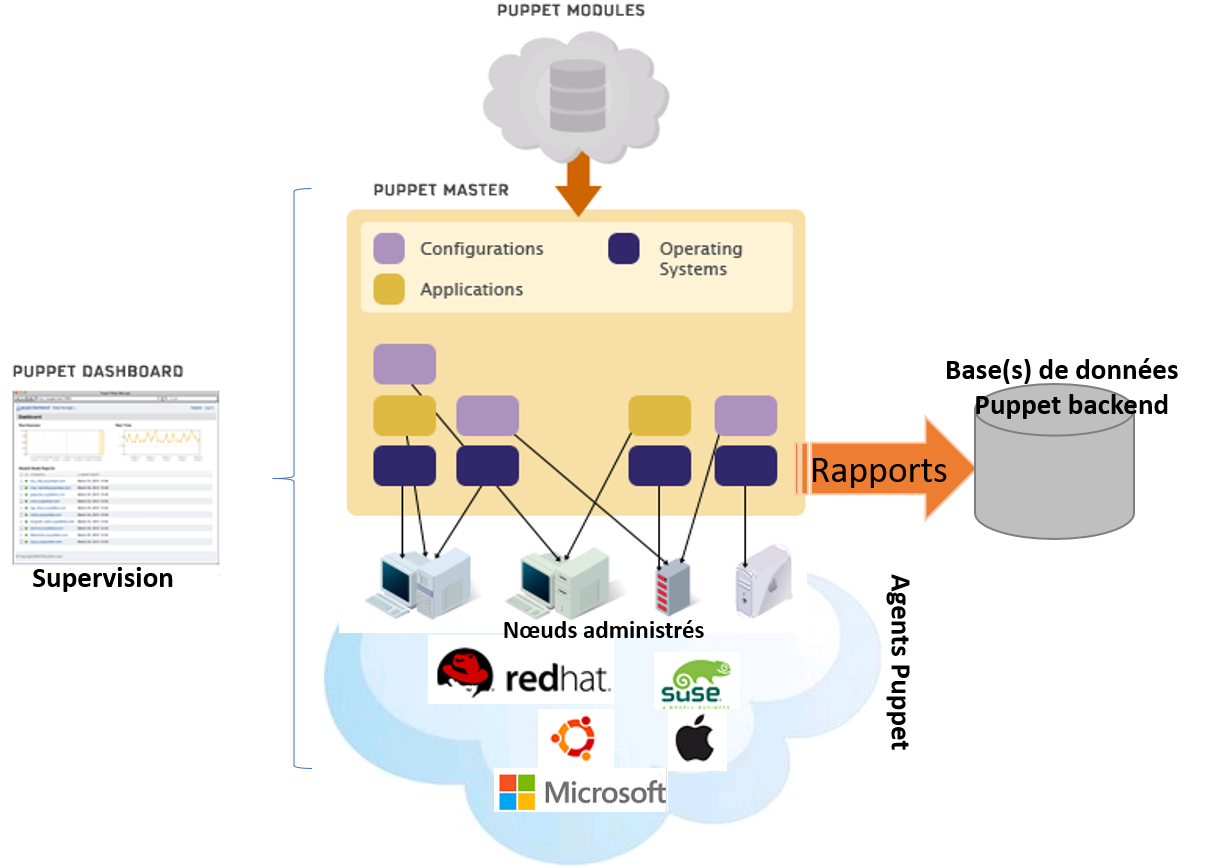
En résumé, l’architecture Puppet tourne autour de quatre grandes fonctions :
• le serveur principal (ou Puppet master)
• le serveur de bases de données (ou PuppeDB aussi appelé Puppet backend)
• le serveur de visualisation (ou Puppet dashboard)
• les clients (ou agents Puppet)
Aussi, de façon pragmatique, il convient d’installer en premier lieu Puppet master afin de le configurer et autoriser la gestion des agents. Ensuite, nous verrons comment installer la base servant à stocker les rapports, également appelée Puppet backend. Nous terminerons notre tour d’horizon avec la configuration du service de visualisation appelé Puppet dashboard, en fournissant quelques règles simples d’utilisation de la commande puppet.
REMARQUE : pour illustrer clairement les différentes fonctionnalités, nous adopterons une architecture à trois serveurs : un pour le Puppet master, un pour la Puppet backend et un dernier pour le Puppet dashboard. Dans notre exemple, il s’agit de trois machines virtuelles en CentOS6.8. Les clients, quant à eux, font partie d’un parc de serveurs en CentOS6, RedHat 6 ou CentOS7.
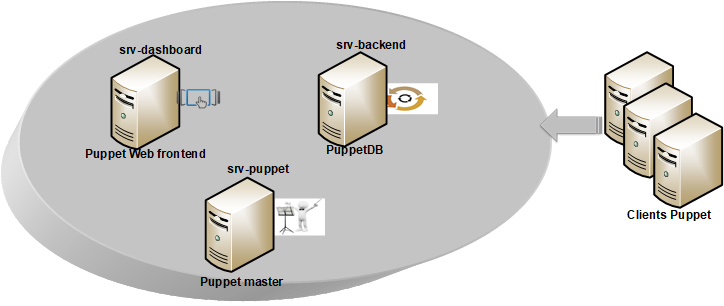
II. Installation et configuration de Puppet master
Pour cette partie, il faut alors installer le package puppet-server en utilisant le gestionnaire de package de la distribution sur laquelle on se trouve. Dans notre exemple, nous adopterons une distribution CentOS 6.
REMARQUE : entre la version CentOS6 et CentOS7 il existe une véritable rupture applicative. En effet, dans le premier cas, la version Puppet fournie est la version 3.8 alors qu’en CentOS7 il s’agit de la version 4. Comme on s’en doute les deux ne sont pas compatibles et seule, la version 3.8 pourra gérer les plateformes les plus anciennes.
Suite à cette remarque, il faut donc choisir judicieusement la version Puppet à activer sur le nœud maître. Afin de faciliter un peu les choses on peut autoriser le site http://yum.puppetlabs/com/el pour pouvoir se créer un dépôt et récupérer les différentes versions de l’outil, depuis le site officiel. Selon la version du nœud à administrer, on pourra ainsi récupérer l’une des deux versions Puppet agent ci-dessous:
# wget -nc --reject *.html -np -r http://yum.puppetlabs.com/el/7Server/products/x86_64/ # wget -nc --reject *.html -np -r http://yum.puppetlabs.com/el/6Server/products/x86_64/
Dans notre cas, nous opterons pour un dépôt constitué du fichier puppet.repo suivant, placé dans le répertoire /etc/yum.repos.d (où reposrv représente le serveur contenant l’ensemble des dépôts officiels de notre parc):
[puppet_products] name= Puppet products $releasever - $basearch baseurl=http://reposrv/repo/yum.puppetlabs.com/el/6Server/products/$basearch/ enabled=1 gpgcheck=0 [puppet_dependencies] name= Puppet dependencies $releasever - $basearch baseurl=http://reposrv/repo/yum.puppetlabs.com/el/6Server/dependencies/$basearch / enabled=1 gpgcheck=0 [puppet_devel] name= Puppet devel $releasever - $basearch baseurl=http://reposrv/repo/yum.puppetlabs.com/el/6Server/devel/$basearch/ enabled=1 gpgcheck=0
On peut alors procéder à l’installation du service Puppet sur le Puppet master via l’instruction suivante :
# yum install puppet-server puppet
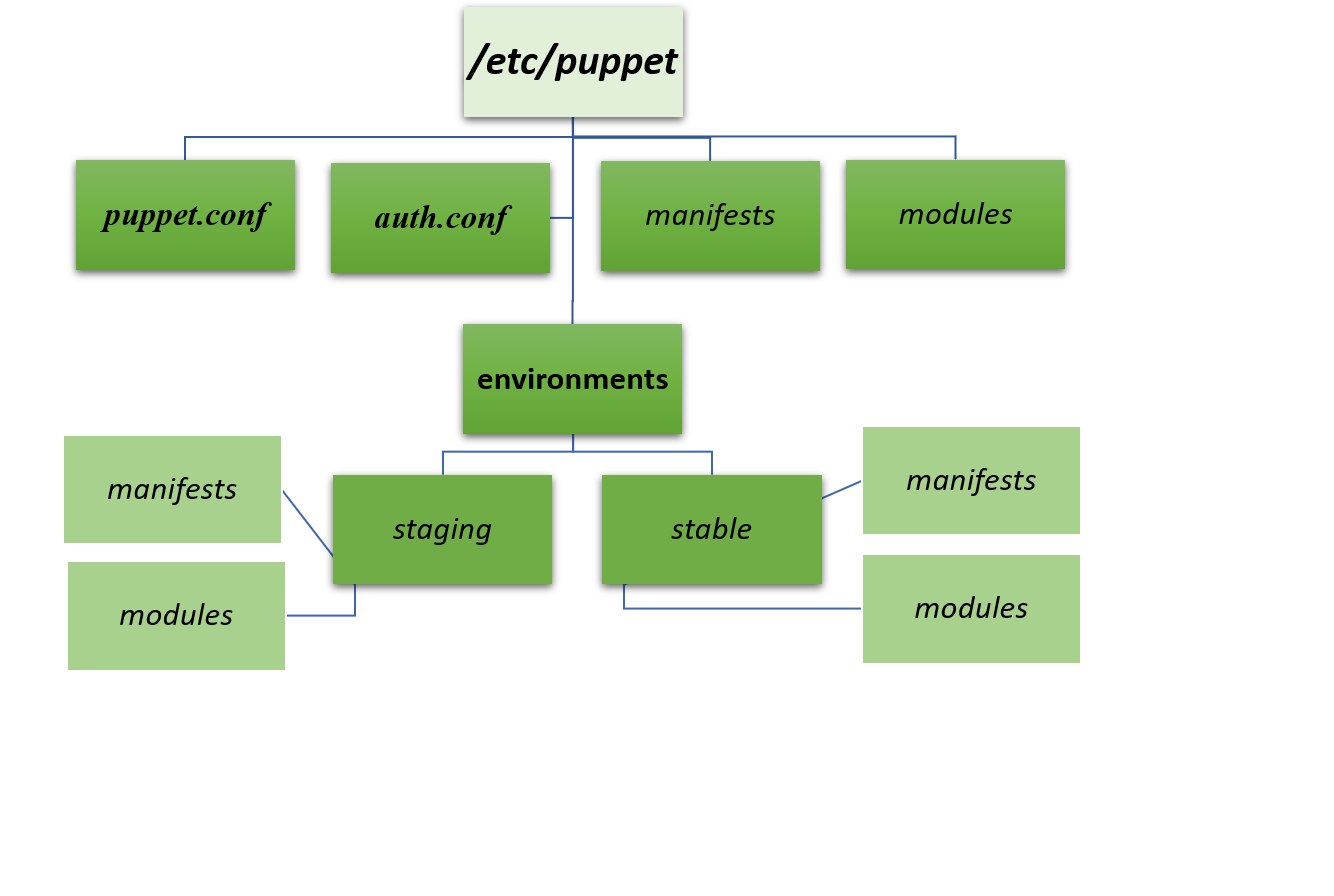
Dès lors, on se retrouve alors avec une nouvelle arborescence /etc/puppet, dans laquelle on devrait alors découvrir les trois fichiers suivants :
• puppet.conf : contenant la configuration utilisée par le logiciel, tant pour la partie cliente que pour sa configuration de serveur maître. On peut y préciser, entre autre, le nom du serveur Puppet, l’intervalle entre chaque demande des clients vers le serveur.
REMARQUE : la plupart du temps, la configuration par défaut convient parfaitement. Il est à noter que dans le cas du serveur maître, il faut le configurer à la fois en tant qu’agent mais aussi en tant que serveur. Donc, ce fichier contiendra deux rubriques, contrairement aux nœuds administrés qui n’en contiendront qu’une seule.
• auth.conf : ce fichier spécifie les clients ou le nœuds pouvant accéder aux différents modules (ou manifestes). Par défaut, l’ensemble des nœuds auront accès à l’intégralité des modules.
Hors ces fichiers, il existe également deux sous-répertoires manifests et modules. Mais, nous ne les utiliserons pas tels que. En effet, nous préférons positionner un sous-répertoire environments, dans lequel nous placerons deux sous-répertoires :
• un sous-répertoire pour l’environnement de tests appelé staging
• un sous-répertoire pour l’environnement de production appelé stable
On aura ainsi la possibilité de tester dans un environnement dédié, l’ensemble des développements ainsi que le code, des différents manifestes réalisés. L’arborescence aura donc la présentation suivante :
ATTENTION : une ancienne version du package puppet-server existe également dans le dépôt EPEL. Il faut obligatoirement effectuer l’installation du package avec celui diffusé depuis le dépôt, mentionné ci-dessus, et référencé dans le fichier puppet.repo du répertoire /etc/yum.repos.d.
Il est possible avant installation de vérifier la version du package que l’on s’apprête à installer en exécutant la commande suivante :
# yum info puppet-server Installed Packages Name : puppet-server Arch : noarch Version : 3.8.7 Release : 1.el6 Size : 10 k Repo : installed …
Le service Puppet, au niveau du Puppet master s’exécute via le daemon puppetmasterd (le service, quant à lui s’appelle puppetmaster), sur le port TCP/8140, via l’utilisateur puppet, créé automatiquement dès l’installation du package. Les communications entre le serveur et les nœuds administrés sont chiffrées et fonctionnent au travers d’une PKI intégrée et d’un serveur de fichiers.
Contrairement aux autres services client/serveur, dans le cas de Puppet, c’est le client qui pousse les informations à l’intention du daemon puppetmasterd, grâce à la notion de "facter", permettant d’extraire sous forme de variables d’environnement les différentes caractéristiques du client. On pourrait donc représenter le protocole d’échange de la façon suivante :
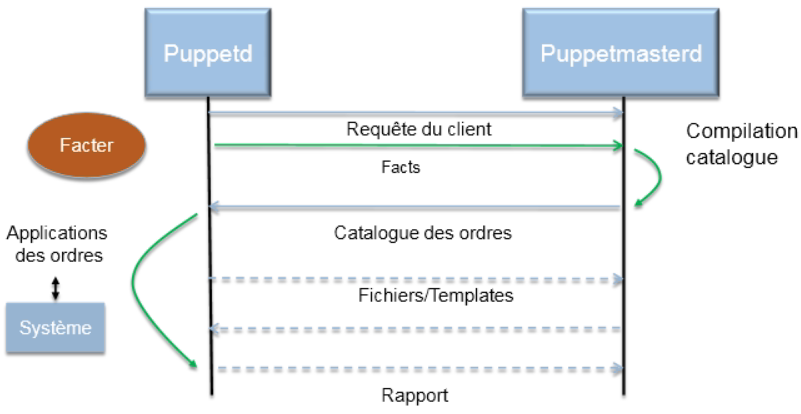
ATTENTION : afin de ne pas perturber les échanges entre clients et serveur, il est fortement conseillé de désactiver tout service type SELinux ou AppArmor.
La PKI utilisée par Puppet sert à sécuriser les échanges entre le serveur et ses clients. Ces derniers réclament alors une signature de leur certificat auprès du Puppet master. Cela offre également la possibilité de révoquer ledit certificat à tout instant. Ce système est adossé au protocole REST (REpresentational State Transfer).
REMARQUE : il s’agit d’une architecture permettant de construire des applications web, utilisant les spécifications originelles du protocole http plutôt que de réinventer une nouvelle surcouche, comme le font les modèles SOAP et/ou XML-RPC. Si l’on détaille alors les échanges entre le client et son service, on pourrait schématiser les messages transmis comme ci-dessous :
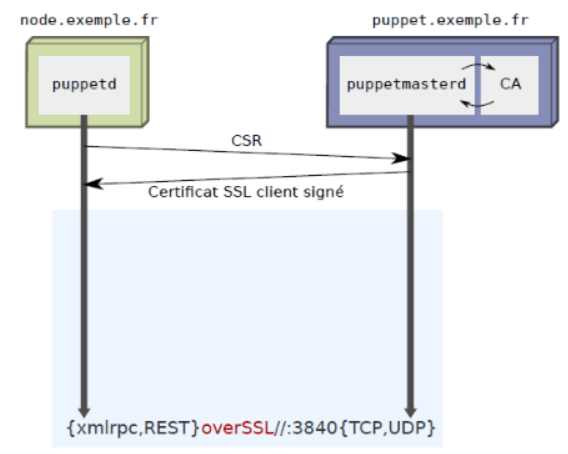
On notera également que l’ensemble des machines (clients ou serveur) sont exprimées au format FQDN (Full Qualified Domain Name), nécessitant de fait, une déclaration officielle au sein d’un ou plusieurs serveurs de noms DNS. Il s’agit ni plus ni moins de la condition sine qua none pour que la PKI puisse fonctionner correctement.
Éditons maintenant le fichier de configuration puppet.conf et détaillons un peu les principales variables qui s’y trouvent. En premier lieu, on va voir deux sections :
• la section [main] décrivant les variables principales.
• la section [master] décrivant les variables propres au Puppet master.
Dans la section [main], on peut laisser les trois variables suivantes :
• logdir décrivant l’emplacement des journaux de traces
• rundir décrivant l’emplacement du fichier où est stocké le n° de processus (pid)
• ssldir décrivant le répertoire où se trouvent le matériel de chiffrement SSL.
Par défaut, tout changement ou modification génère automatiquement un rapport situé sur le serveur maître, dans le répertoire /var/lib/puppet/reports. Mais, on peut tout fait choisir une autre destination en modifiant alors la variable reportdir. Au niveau de la rubrique [master], on devrait avoir les lignes suivantes :
[master] # ssl_client_header = HTTP_X_CLIENT_DN # ssl_client_verify_header = HTTP_X_CLIENT_VERIFY manifest = $confdir/environments/$environment/manifests/site.pp modulepath = $confdir/environments/$environment/modules reports = store # reports = puppetdb, http ca = true storeconfigs_backend=puppetdb storeconfigs=false # external_nodes = /etc/puppet/external_node # node_terminus = exec
REMARQUE : les lignes commençant par le caractère ‘#’ représentent des commentaires. On peut les supprimer. La variable $confdir représente l’emplacement où a été installé Puppet. Dans notre exemple, il s’agit de /etc/puppet. De même, la variable $environments représente l’environnement staging ou stable (selon le cas). Elle sera renseignée en fonction des commandes appliquées.
Lorsque l’on n’utilise pas Apache, on peut désactiver les champs concernant SSL. Afin de s’assurer que le service Puppet fonctionne correctement, dans un premier temps, nous allons générer uniquement des rapports au format texte, impliquant le paramètre reports=store. Par la suite, on pourra commenter cette ligne et la remplacer par celle positionnée en dessous : reports = puppetdb, http.
A ce stade, on doit alors éditer le fichier site.pp se trouvant dans le répertoire /etc/puppet/environments/stable/manifests pour décrire la liste des nœuds à administrer en commençant par le Puppet master :
node srv-puppet {
}
Le daemon puppetmasterd peut alors être démarré en exécutant la commande ci-dessous :
# /etc/init.d/puppetmaster start
La vérification peut s’effectuer au travers de l’interrogation du port d’écoute du service grâce à la commande netstat :
# netstat -anp|grep 8140 tcp 0 0 0.0.0.0:8140 0.0.0.0:* LISTEN 896/ruby
Le Puppet master, comme nous l’avons déjà souligné est également client (ou agent) de sa propre architecture. C’est pourquoi, dans le fichier puppet.conf on doit également déclarer la configuration en tant qu’agent :
[agent] classfile = $vardir/classes.txt localconfig = $vardir/localconfig server = srv-puppet.mydmn.org report = true environment = stable runinterval = 30m pluginsync = true
REMARQUE: contrairement à Ansible, Puppet nécessite un agent sur les clients pour dialoguer avec eux. Bien évidemment, le serveur maître est à la fois le maître et l'agent.
En tant que tel, on peut donc également interroger les certificats du serveur et vérifier que celui-ci est bien signé (c’est-à-dire préfixé par le symbole ‘+’ :
# puppet cert –la … + "srv-puppet.mydmn.org" (SHA256) 80:8C:D4:…::93:CD (alt names: "DNS:puppet", "DNS:srv-puppet.mydmn.org", "DNS:srv-puppet.mydmn.org")
III. Installation et configuration de Puppet agent
Côté client, on peut installer le package puppet sur les deux premiers serveurs Puppet backend et Puppet dashboard, en exécutant l’instruction suivante (et en ayant au préalable ajouté le fichier puppet.repo dans /etc/yum.repos.d):
# yum install puppet
Le fichier de configuration puppet.conf se trouve également dans le répertoire /etc/puppet et on doit y déclarer les lignes suivantes :
[main] logdir = /var/log/puppet rundir = /var/run/puppet ssldir = $vardir/ssl [agent] classfile = $vardir/classes.txt localconfig = $vardir/localconfig server = srv-puppet.mydmn.org report = true environment = stable runinterval = 30m pluginsync = true
On doit alors sauvegarder ce fichier et initialiser le service puppet afin de le rendre automatique lors des prochaines phases de redémarrage du serveur :
# chkconfig puppet on
REMARQUE : l’ensemble des mises à jour peuvent être exécutées manuellement grâce à la commande suivante :
# puppet agent -t
Dans le cas contraire, un délai de 30 minutes sera respecté entre chaque synchronisation, comme spécifié dans le fichier de configuration puppet.conf via la variable runinterval. Dans le cas où l’on veut tester ce mécanisme de façon automatique, on peut repasser cet intervalle à 1minute. En règle générale, cela devrait fonctionner. Mais, si l’on reçoit le message ci-dessous, c’est que l’on a oublié d’autoriser le port au niveau du pare-feu :
Info: Creating a new SSL key for srv-backend.mydmn.org Error: Could not request certificate: No route to host - connect(2) Exiting; failed to retrieve certificate and waitforcert is disabled
On doit alors autoriser le port TCP/8140 à traverser le firewall et exécuter la commande iptables suivantes :
# iptables -A INPUT -m state --state NEW -m tcp -p tcp --dport 8140 -j ACCEPT
Comme on vient de modifier la configuration du pare-feu, on doit alors redémarrer le service iptables :
# service iptables restart
Dans le cas où la vérification se passe bien, on devrait recevoir un message du type "Exiting; no certificate found and waitforcert is disabled". Cela signifie que l’on peut manuellement signer le certificat des nouveaux clients : # puppet cert -s srv-backend.mydmn.org srv-dashboard.mydmn.org
On notera que l’on peut signer les certificats de plusieurs clients en simultané, simplement en les passant les un après les autres sur la ligne de commande. A l’opposé, la révocation d’un certificat se fait en exécutant la commande ci-dessous :
# puppet cert -rc <Server FQDN>
De façon plus Générale, si l’on souhaite révoquer un certificat de façon définitive, il suffit d’exécuter la commande ci-dessous au niveau du Puppet master :
# puppet cert clean <Server FQDN>
Si on rencontre un problème avec le certificat d’un client, il suffit de se placer dans le répertoire /var/lib/puppet du client concerné et supprimer le sous-répertoire ssl afin qu’il soit automatiquement recréé lors de la phase de signature du certificat:
# cd /var/lib/puppet # rm -fR ssl
REMARQUE: il faut se souvenir de correctement déclarer les clients au niveau des serveurs de noms DNS. Dans le cas contraire, l’automatisation ne fonctionnera pas correctement.
Lorsque l’on déclenche manuellement une première découverte du client, on obtient l’affichage suivant :
Error: Could not retrieve catalog from remote server: Error 400 on SERVER: Could not find default node or by name with 'srv-backend.mydmn.org Warning: Not using cache on failed catalog Error: Could not retrieve catalog; skipping run
Cela s’explique par le fait que l’on ne dispose pas encore de fiche descriptive (même vierge), comme on l’a fait précédemment pour le serveur srv-puppet, au sein du fichier site.pp. On peut alors considérer avec ces deux configurations que le serveur Puppet master est prêt à fonctionner correctement. Mais, avant d’aller plus loin, il faut peut-être expliquer comment décrire un manifeste.
ATTENTION : à ce stade, on peut copier le fichier site.pp (du répertoire /etc/puppet/environments/stable/manifests/), dans le répertoire /etc/puppet/environments/staging/manifests afin de disposer de la même configuration que pour l’environnement de production.
IV. Création d'un nouveau module
Dans le cadre de Puppet, tout nouveau module doit disposer d’un fichier init.pp équivalent, placé dans le répertoire /etc/puppet/environments/stable/modules/<Module>/manifests. Ce fichier va alors décrire la ou les ressources à configurer. Ces dernières peuvent être :
• des packages
• des utilisateurs ou des groupes
• des fichiers
• des systèmes de fichiers
• des partitions
• des jobs
• des processus
…
Chaque répertoire de module doit contenir au minimum trois sous-répertoires :
• un répertoire manifests contenant le fichier init.pp de description
• un répertoire files contenant les fichiers manipulés
• un répertoire templates contenant les modèles des fichiers à manipuler
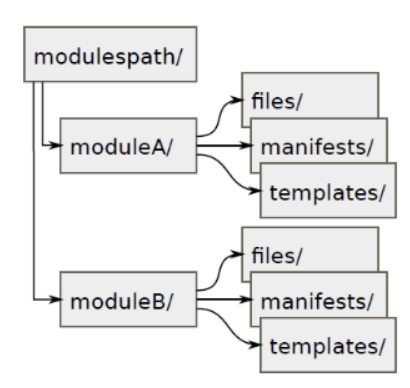
Lorsque l’on souhaite exécuter un test d’un module en particulier il est également possible de préciser l’environnement dans lequel on souhaite le faire :
# puppet agent -t --environments=staging
V. Tâche d'auto-signature et déclaration de modules
Afin de rendre Puppet encore plus pratique à utiliser, nous allons maintenant faire en sorte de signer automatiquement les certificats des nouveaux clients. Il s’agit effectivement d’une tâche répétitive qu’il est fortement conseillé d’automatiser au travers d’une tâche cron. Pour se faire, sur le Puppet master, on va générer un script puppet-autosigne (que l’on peut placer dans le répertoire /root/bin, servant à scanner l’ensemble des fichiers ‘srv-‘ disponibles et générer, dans la foulée, la signature du certificat associé :
#!/bin/bash
host=`puppet cert -la |grep -e srv- | grep -v "+" | awk {'print $1'}`
fqdn=`echo $host | sed -e 's/"//g'`
puppet cert -s $fqdn 2>&1 > /dev/null
la tâche planifiée crontab ne présente alors aucune difficulté. Il suffit simplement d’appeler le script précédent toutes les minutes permettant ainsi de scruter l’architecture Puppet à la recherche de nouveaux clients déclarés :
* * * * * /root/bin/puppet-autosign > /dev/null 2>&1
REMARQUE : il faudra adapter à vos besoins le filtre ‘srv-‘ en fonction du préfixe ou des noms données à vos serveurs. Par ailleurs, si l’on souhaite enrichir les fonctionnalités de Puppet, on peut aller sur le sorte de la forge https://forge.puppetlabs.com. On peut alors télécharger les fichiers tar.gz, les décompresser pour les placer dans le sous-répertoire modules de l’environnement souhaité.
En supplément de l’automatisation de la signature des certificats, on doit également déclarer une classe principale appelée classe ‘common’ permettant d’intégrer par défaut les principaux modules que l’on souhaite voir activés sur de nouveaux clients Puppet. Pour se faire, il faut éditer le fichier site.pp et y déclarer les lignes suivantes :
class common {
include base
include yum
}
# Serveurs Puppet
node srv-puppet {
class{'::common':}
}
node srv-backend {
class{'::common':}
}
node srv-dashboard {
class{'::common':}
…
Il ne reste plus alors qu’à initialiser les trois modules mentionnés ci-dessus :
• le module base permettant d’initialiser les packages principaux
• le module yum permettant de positionner les fichiers .repo nécessaires
• le module puppet permettant d’initialiser le package puppet
Pour le module base, on souhaite, par exemple disposer obligatoirement des packages wget et iotop, on devra alors déclarer dans le fichier init.pp (dans le répertoire /etc/puppet/environments/modules/base/manifests) les lignes suivantes:
class base {
package { 'wget':
name => wget,
ensure => installed
}
package { 'iotop':
name => iotop,
ensure => installed
}
}
En ce qui concerne le module yum, on souhaite positionner automatiquement les fichier .repo dans le répertoire /etc/yum.repos.d du client. Pour se faire, on va placer un exemplaire de ces fichiers dans le répertoire /etc/puppet/environments/stable/modules/yum/files et déclarer le fichier init.pp suivant :
class yum {
file { "/etc/yum.repos.d/epel.repo":
path => '/etc/yum.repos.d/epel.repo',
source => [ "puppet:///modules/yum/epel.repo" ],
}
file { "/etc/yum.repos.d/puppet.repo":
path => '/etc/yum.repos.d/puppet.repo',
source => [ "puppet:///modules/yum/puppet.repo" ],
}
…..
}
Afin de sécuriser un peu plus chaque fichier manipulé, on peut ajouter la notion de group, mode et owner, permettant de préciser respectivement le groupe, les attributs (lecture/écriture/exécution) et le propriétaire du fichier :
file { "/etc/yum.repos.d/epel.repo":
path => '/etc/yum.repos.d/epel.repo',
source => [ "puppet:///modules/yum/epel.repo" ],
group => ‘0’,
mode => ‘640’,
owner => ‘0’
}
Pour connaître les propriétés "facter" d’un fichier, il suffit simplement d’exécuter l’instruction suivante (par exemple, ici avec le fichier epel.repo):
# puppet resource file /etc/yum.repos.d/epel.repo
file { '/etc/yum.repos.d/epel_lan.repo':
ensure => 'file',
content => '{md5}fc7834fa379dc542830b7ef072fd0776',
ctime => 'Thu Sep 13 08:48:06 +0200 2018',
group => '0',
mode => '644',
mtime => 'Tue Oct 11 09:37:47 +0200 2016',
owner => '0',
type => 'file',
}
De façon plus générale, on peut aussi interroger l’ensemble des propriétés "facter" du serveur, en exécutant la commande ci-dessous :
# facter
REMARQUE : de la même façon que l’on a déclaré un module pour positionner les fichiers .repo dans le répertoire /etc/yum.repos.d, on peut également envisager de créer un module pour fixer les fichiers /etc/resolv.conf, /etc/hosts, etc.
VI. Initialisation du Puppet dashboard
Dans les grandes lignes, le serveur Puppet master est maintenant correctement configuré. Il est temps de s’intéresser à la configuration du serveur de visualisation (aussi appelé Puppet dashboard). Pour que le serveur WebUI puisse dialoguer avec son serveur de base de données le Puppet backend, il faut installer les deux packages suivants :
# yum install puppet-dashboard mysql
Le premier permet d’installer les deux programmes de l’interface graphique :
• le script puppet-dashboard qui est l’interface finale de l’application
• le script puppet workers qui est l’interface finale du Puppet backend.
L’application pilotant le programme frontend est localisée dans le répertoire /usr/share/puppet-dashboard. On y trouve le répertoire config ainsi que le fichier de paramétrage de l’interface web, appelé settings.yml (qui comme son extension le suggère est écrit en langage Yaml). On va commencer par configurer les paramètres de la base de données en éditant le fichier database.yml, se trouvant dans le sous-répertoire config. On doit notamment y déclarer les lignes suivantes :
production: database: puppetdashboard_stable username: dashboard password: ******** encoding: utf8 adapter: mysql host: srv-backend
Il n’est pas utile de déclarer le paramétrage d’un environnement de tests car pour les réaliser, il suffit d’utiliser la commande puppet en fournissant le paramètre d’environnement qui est préemptif. On peut donc commenter cette partie et laisser uniquement la déclaration de la rubrique ‘production’ décrite ci-dessus.
Par contre, il peut s’avérer utile de modifier le paramètre time_zone et déclarer alors la ligne suivante :
… time_zone : ‘Paris’ …
Il faut alors redémarrer le service puppet-dashboard afin de prendre en compte les modifications :
# service puppet-dashboard stop # service puppet-dashboard start
VII. Initialisation du Puppet backend
Sur le serveur hébergeant les bases de données de Puppet, on doit maintenant installer le serveur MySQL et le configurer :
# yum install -y mysql-server # /etc/init.d/mysqld start
ATTENTION : si l’on dispose d’un pare-feu local, il faut penser à autoriser le port TCP/3306 de l’instance MySQL en ce qui concerne les filtrages des tables netfilter et recharger la configuration du pare-feu:
# iptables -A INPUT -m state --state NEW -m tcp -p tcp --dport 3306 -j ACCEPT # service iptables reload
A l’initialisation de l’instance MySQL, le compte root n’a aucune valeur. Mais, après la création de la base de stockage des rapports Puppet, l’accès sera sécurisé. Cette création s’effectue en exécutant les commandes suivantes (en remplaçant les ‘*’ du mot de passe par votre propre mot de passe) :
# mysql -u root mysql> create database puppetdashboard_stable; mysql> create user 'dashboard'@'%' IDENTIFIED BY '*******'; mysql> GRANT ALL PRIVILEGES ON puppetdashboard_stable.* TO 'dashboard'@'%'; mysql> ALTER DATABASE puppetdashboard_stable CHARACTER SET utf8;
Une fois cela réalisé, on peut d’ores et déjà tester la connectivité depuis n’importe quel client MySQL (par exemple depuis le serveur srv-dashboard) via l’instruction ci-dessous :
# mysql -h srv-backend -u dashboard -p puppetdashboard_stable
Si tout est bien configuré, on devrait alors voir apparaître le prompt ‘mysql>’ en guise de réponse à notre commande. On va alors pouvoir intégrer les structures de données propres à la base Puppet dashboard. On doit donc se connecter au serveur WebUI et se placer dans le répertoire /usr/share/puppet_dashboard et y exécuter la commande ci-dessous :
# rake RAILS_ENV=production db:migrate
Ceci dit, une base de données possède une vie propre, il peut donc être judicieux de purger régulièrement la base, via un script flush_oldreport.sh que l’on pourra placer dans le répertoire /root/Scripts du serveur Puppet dashboard :
# cd /usr/share/puppet_dashboard # rake RAILS_ENV=production reports:prune upto=1 unit=mon 2>&1 > /var/log/rake_flush.log
Il ne restera plus alors qu’à créer une tâche planifiée permettant de réaliser ce ménage, par exemple, tous les quatre mois à l’occasion du premier samedi du mois concerné:
0 6 * */4 7 /root/Scripts/flush_oldreport.sh
Il est alors possible de démarrer le service puppet-dashboard en exécutant la commande suivante :
# /etc/init.d/puppet-dashboard start
REMARQUE: le service puppet-dashboard doit toujours être démarré en premier, avant le service puppet-dahsboard-workers. Il faut malgré tout rendre ces deux services totalement automatique lors des redémarrages :
# chkconfig puppet-dashboard on # chkconfig puppet-dashboard-workers on
On peut ensuite démarrer le second service puppet-dashboard-workers. Toutefois, les rapports sont pour le moment générés au format texte et ne sont donc pas reportés sur la console Web. Si l’on souhaite les voir apparaître, il faut alors modifier le fichier de configuration puppet.conf du Puppet master et mentionner les lignes ci-dessous dans la rubrique [master]:
… reports = store, http reporturl = http://srv-dahsboard:3000/reports/upload …
De ce fait, il faut penser aussi à autoriser le port TCP/3000 au niveau du pare-feu local. Après un redémarrage du service Puppet principal et en rafraîchissant la page web sur notre navigateur préféré, on devrait voir apparaître le message suivant :
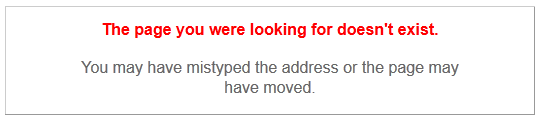
Ceci est plutôt encourageant, même si ce n’est pas encore totalement satisfaisant. En fait cela s’explique par le fait qu’il n’y a pas encore de rapport dans la base, à présenter. Mais, dès l’exécution d’une tâche agent, depuis n’importe quel client Puppet, le premier rapport va alors apparaître et on devrait visualiser la fenêtre suivante :
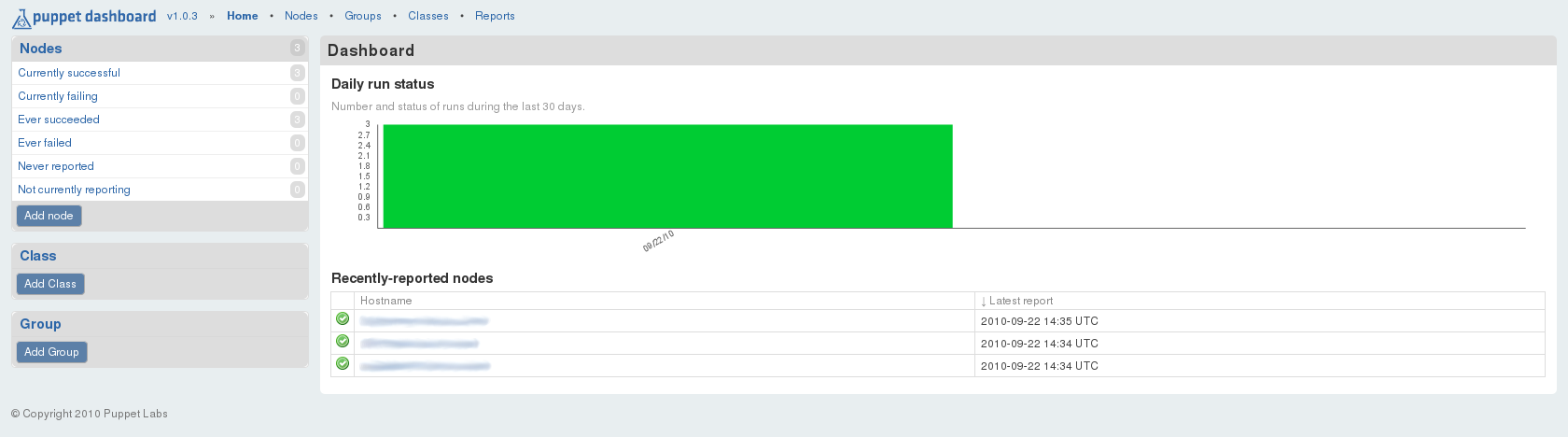
En ce qui concerne les clients Puppet, il est possible de simuler une passe Puppet, en exécutant ce que l’on appelle un "dry run", exprimé via l’option noop de la commande :
# puppet agent -t --environment=stable --noop
Il est également envisageable d’activer les daemons Puppet dans ce mode noop afin de simuler les générations de rapports, sans les appliquer véritablement en journée et pouvoir les programmer pour la nuit suivante, après une vérification méthodique. Les changements effectués sur les différents clients apparaissent au niveau de l’interface graphique du tableau de bord avec des codes couleur distincts :
• en bleu pour un client modifié
• en gris pour une machine non accessible
• en rouge pour une connexion échouée
• en vert pour l’ensemble des clients non modifiés
VIII. Conclusion
Voilà, maintenant que la mécanique est en place, il ne reste plus qu’à écrire les différents modules. Mais, me direz-vous que peut-on faire encore ? Beaucoup de tâches répétitives peuvent être totalement automatisées :
• la découverte de nouveaux clients Puppet
• l’installation de nouveaux serveurs Linux
• la création de nouvelles machines virtuelles
• la modélisation des fichiers standards (resolv.conf, hosts…)
• l’installation de logiciels (Oracle, Shinken, Apache…)
Avec cette technique, on peut aller très loin dans les procédures d’automatisation. D'autant, que Puppet favorise le développement de bibliothèques de modules permettant d’appeler des modules déjà réalisés au sein de nouveaux manifestes. Ainsi, finies les corvées d’installation, de clonage ou de réplication. Il suffit simplement de rédiger la ou les recettes permettant d’effectuer les différentes tâches que l’on avait à mener à bien en plusieurs étapes auparavant en exécutant un simple appel à Puppet.
REMARQUE : ce tutoriel n’est qu’un aperçu, bien sûr de la puissance de Puppet, mais, je vous invite vivement à consulter la documentation concernant le langage de programmation de cet outil extraordinaire.
A ce jour, de nombreux autres programmes similaires à Puppet font leur apparition, tels que ansible, chef, expect, ou encore rudder. Tous ont leurs avantages et inconvénient et chaque administrateur a ses préférences pour l’un ou l’autre. Mais, il est essentiel de passer par l’un de ces logiciels pour gagner un temps précieux en mise au point et clarté d’administration.