

Linux : qu’est-ce que la charge système « load average » sur une machine ?
Sommaire
I. Présentation
Sur Linux, il y a un indicateur très intéressant pour connaître la charge générale d'une machine : la charge système appelée "load average" (charge moyenne, en français). Comment interpréter cette information ? C'est ce que nous allons voir dans ce tutoriel.
Imaginez que votre serveur web ralentisse soudainement : d'où vient le problème ? Du serveur Web ? De la base de données ? Ou encore d'un autre service sur le système ? Et surtout, où se situe la saturation : CPU, RAM, etc... La charge système (ou Load Average) aide à mieux comprendre ce qu'il se passe.
Si vous utilisez Linux, vous avez probablement déjà exécuté la commande top, et donc vous avez déjà vu une ligne comme celle-ci :
load average: 0.18, 0.15, 0.10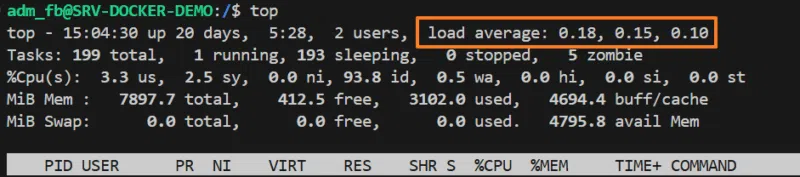
C'est de cette ligne que nous allons parler dans la suite de ce tutoriel.
II. Qu'est-ce que le "Load Average" ?
Le terme Load Average désigne la moyenne de la charge du système sur une période donnée. Contrairement à une idée reçue, sous Linux, cette valeur ne représente pas uniquement l'utilisation du processeur (CPU). Le processeur a ses propres indicateurs. La Load Average indique plutôt, grossièrement, à quel point le système est occupé.
Il faut voir la charge moyenne sous Linux comme la taille de la file d'attente globale du système : elle regroupe les processus qui travaillent, ceux qui attendent le processeur, et ceux qui patientent après le disque. Il s'agit donc des processus en cours d'exécution, de ceux en attente d'exécution, et de ceux bloqués car ils attendent après une ressource matérielle.
Ce qu'il est important de comprendre, c'est que la charge système peut être élevée, même si le processeur est très peu sollicité. En effet, le goulot d'étranglement au niveau des performances de la machine peut venir des I/O disques.
III. Analyser les valeurs : 1, 5 et 15 minutes
Lorsque vous tapez la commande top, le système vous renvoie trois nombres. Par exemple :
load average: 0.18, 0.15, 0.10Ces trois valeurs représentent la moyenne de la charge sur trois périodes distinctes :
- 1 minute : la charge moyenne sur la dernière minute.
- 5 minutes : la charge moyenne sur les 5 dernières minutes.
- 15 minutes : la charge moyenne sur les 15 dernières minutes.
L'analyse de ces trois chiffres permet de dégager une tendance, et ça, c'est vraiment très intéressant :
- Si 1 min > 15 min (par exemple : 1.80, 1.20, 0.50) : la charge de la machine augmente. Le problème est en cours et la situation s'aggrave.
- Si 1 min < 15 min (par exemple : 0.50, 1.20, 1.80) : la charge de la machine baisse. Le pic d'activité est passé !
- Si les valeurs sont proches : la charge est stable.
Si vous administrez des serveurs Linux, c'est vraiment une notion à retenir.
Voici un résumé :

IV. La relation avec les cœurs CPU
La charge système ne représente pas directement la charge du processeur, mais elle est liée malgré tout : c'est normal, il est au cœur du réacteur de l'ordinateur. En réalité, une valeur brute comme 2.00 ne veut pas dire grand-chose si l'on ne connaît pas le nombre de cœurs (ou vCPU) disponibles sur une machine.
- Sur un système mono-cœur (1 CPU) : une charge de
1.00signifie que le processeur est occupé à 100%. Si la charge monte à2.00, cela signifie qu'il y a deux fois plus de travail que le processeur ne peut en traiter, soit une charge potentielle de 200% : une file d'attente se forme obligatoirement. - Sur un système quad-cœur (4 CPU) : une charge de
1.00signifie que seulement un cœur du processeur est occupé à 100% (ou les 4 à 25%). Le système a encore 75% de ressources disponibles. Donc, si vous avez bien suivi, sur ce serveur, la saturation commence à partir d'une Load Average à4.00(soit le nombre de CPU !).
Pour savoir combien de CPU a votre machine, vous pouvez lancer cette commande :
nproc
# Par exemple :
2
# Si vous êtes curieux, vous pouvez afficher tous les détails sur votre processeur
cat /proc/cpuinfo
# Vous pouvez filtrer la commande précédente :
cat /proc/cpuinfo | grep processor | wc -lPour savoir si votre système est surchargé, vous pouvez appliquer la règle suivante : divisez la charge système par le nombre de cœurs logiques. Si le résultat est supérieur à 1.0, alors surveillez l'état de votre machine : il y a une surcharge plus ou moins importante, on peut être à 1.10 comme à 18.0.
V. Les commandes pour afficher la charge système
Voici quelques exemples d'outils et de commandes que vous pouvez utiliser pour afficher la charge système.
A. Uptime
C'est la commande la plus simple pour avoir l'information brute, sans trop d'information autour. Elle affiche avant tout l'uptime Linux, mais elle est accompagnée par la Load Average.
uptime
15:41:12 up 20 days, 6:05, 2 users, load average: 0.04, 0.05, 0.06B. Top / Htop : l'analyse temps réel
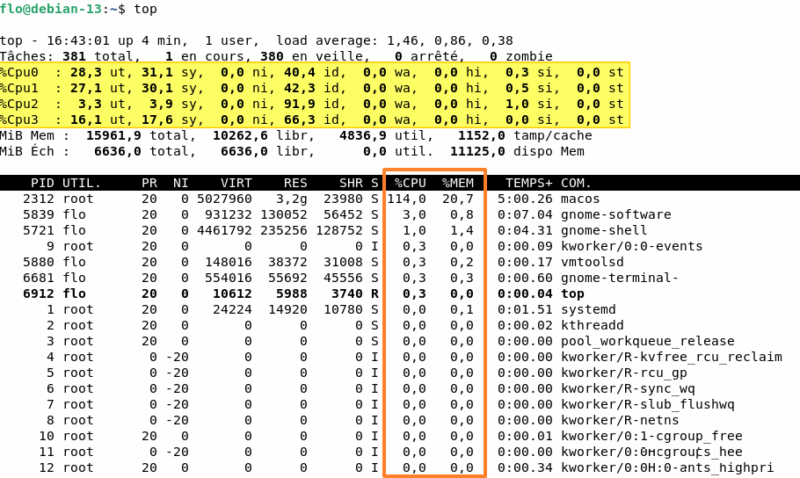
Sur Linux, top est installé par défaut sur toutes les distributions (ou presque). En complément, l'outil htop (à installer à l'aide des dépôts officiels) est plus visuel et convivial. Ces deux outils permettent de voir quels processus consomment le plus.
topAstuce avec la commande top : appuyez sur la touche 1 de votre clavier pour voir le détail de chaque cœur CPU.
C. Vmstat
La commande vmstat, disponible nativement sur Linux, est aussi utile puisqu'elle affiche des statistiques sur la charge du système. Par exemple, voici le résultat qu'elle peut retourner :
vmstat
procs ----------mémoire---------- -échange- -----io---- -système- ------cpu--------
r b swpd libre tampon cache si so bi bo in cs us sy id wa st gu
2 0 0 9545744 49188 1199512 0 0 3332 467 3550 6 15 7 52 0 0 26Cette sortie est statique, si l'on veut qu'elle soit plus dynamique, c'est possible. Voici un exemple pour effectuer 10 relevés avec 1 seconde d'intervalle.
vmstat 1 10
procs ----------mémoire---------- -échange- -----io---- -système- ------cpu--------
r b swpd libre tampon cache si so bi bo in cs us sy id wa st gu
3 0 0 9577136 49288 1199496 0 0 3077 434 3488 6 14 7 54 0 0 26
1 0 0 9577136 49288 1199496 0 0 0 0 3102 2640 1 4 71 0 0 25
2 0 0 9576896 49288 1199496 0 0 0 0 3027 2434 1 3 72 0 0 24
2 0 0 9576896 49288 1199496 0 0 0 84 2905 2296 1 3 73 0 0 24
2 0 0 9576896 49288 1199496 0 0 0 0 2669 1941 1 3 72 0 0 24
2 0 0 9576896 49288 1199496 0 0 0 0 2954 2551 1 5 72 0 0 23
2 0 0 9576896 49288 1199496 0 0 0 0 2614 1848 1 4 72 0 0 22
1 0 0 9576896 49288 1199496 0 0 0 0 2545 1927 0 3 73 0 0 24
1 0 0 9576896 49288 1199496 0 0 0 0 2619 1962 0 3 73 0 0 24
1 0 0 9576896 49288 1199496 0 0 0 0 2639 1982 1 2 72 0 0 25La première ligne de vmstat affiche la moyenne depuis le dernier démarrage du serveur. Elle ne reflète pas l'instant présent. Elle nous dit juste qu'à un moment donné (probablement au démarrage), le serveur a beaucoup lu sur le disque. Il faut donc ignorer la première ligne pour un diagnostic temps réel.
La sortie de la commande vmstat est organisée en plusieurs sections (processeurs, mémoire vive, SWAP, I/O disque, système, et processeur). Il y a aussi deux colonnes liées aux processus qui méritent une attention particulière :
- La colonne
r: elle correspond à larun queue, c'est-à-dire les processus déjà en cours d'exécution ou prêtes à l'être. - La colonne
b: elle correspond à lablocked queue, c'est-à-dire les processus en attente d'exécution et bloqués, car en attente de la libération d'une ressource.
D. Glances
Pour avoir une visibilité globale sur l'état de votre système, je vous recommande d'utiliser Glances. Cet outil open source offre une vue plus détaillée en comparaison de la commande top.
Vous pouvez le découvrir dans ce tutoriel :
Ce qui est pratique avec Glances, c'est qu'il affiche la Load Average ainsi que le nombre de cœurs CPU. Inutile de chercher, tout y est.

VI. Simuler une charge système sur Linux
Si vous voulez simuler une charge système sur une machine Linux (de test, bien entendu), vous pouvez installer le paquet suivant :
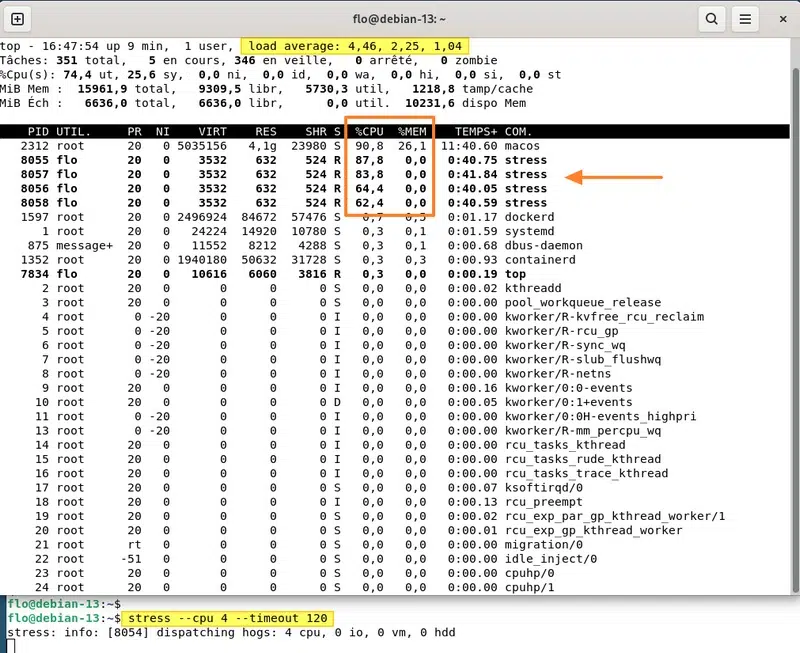
sudo apt update && sudo apt install stressPuis, vous pouvez simuler une montée en charge du CPU. L'exemple ci-dessous sollicite 4 CPU pendant 2 minutes (120 secondes).
stress --cpu 4 --timeout 120
stress: info: [8054] dispatching hogs: 4 cpu, 0 io, 0 vm, 0 hdd
stress: info: [8054] successful run completed in 120sL'effet est immédiat, et la charge système augmente progressivement. Surtout, avec la commande top, nous pouvons identifier les processus à l'origine de cette charge. Même si ce n'est qu'une simulation, dans un cas réel, un processus lié à MariaDB ou MySQL peut être à l'origine d'une augmentation de la charge (une requête SQL bloquée, par exemple).
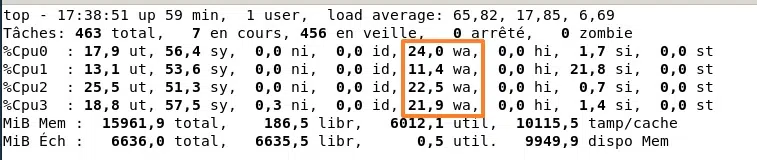
Vous pouvez aussi solliciter plutôt le disque avec un test de charge, plutôt que le CPU. Attention, cette commande va écrire beaucoup de données sur votre disque (il peut saturer si c'est une VM avec peu de ressources).
stress --hdd 8 --timeout 30Ici, avec la commande top, on constate que la charge est très élevée (plus de 65 sur la dernière minute), mais que le CPU se porte bien. Ce qui change en comparaison de la charge CPU, c'est la valeur wa : elle est élevée, c'est un signe intéressant qui montre une saturation au niveau du disque. Avec le test de stress CPU, elle était à 0.
VII. Conclusion
Le Load Average est un indicateur essentiel qu'il faut connaitre si vous administrez des machines Linux, que ce soit des serveurs ou des postes de travail. C'est un indicateur pertinent et fiable.
Voici quelques points à vérifier pour identifier d'où vient la lenteur :
- Consultez la liste des processus afin d'identifier un service qui solliciterait beaucoup le processeur ou le disque,
- Contrôlez les tâches planifiées de la machine (crontab) : une tâche est peut être encore en cours d'exécution (une tâche nocturne qui s'éternise),
FAQ
Quelle est la valeur idéale du Load Average ?
Idéalement, elle doit être inférieure au nombre de cœurs de votre processeur. Sur un système avec 1 CPU, cela signifie maintenir une charge système en dessous de 1.0. Sinon, c'est qu'un processus consomme trop de ressources, ou peut-être que la machine est sous-dimensionnée.
Un Load Average élevé signifie-t-il toujours que la machine est lente ?
Non, pas nécessairement, puisque c'est à comparer avec le nombre de CPU. Si vous avez beaucoup de cœurs, un chiffre élevé (comme 10 sur un serveur 32 cœurs) n'est pas gênant.
Pourquoi mon Load Average est haut alors que le CPU est à 0% ?
C'est probablement dû aux I/O (Entrées/Sorties) au niveau du disque. Des processus sont bloqués en attente du disque dur ou de l'espace de stockage réseau (connecté en NFS, par exemple), ce qui augmente la charge sans utiliser le CPU.
Comment voir le nombre de CPU sur mon serveur ?
Le plus simple, exécutez la commande suivante : nproc.
Où sont stockées les valeurs de Load Average dans le système ?
Elles sont lisibles dans le fichier virtuel /proc/loadavg. Les commandes comme uptime et top ne font que lire ce fichier.









