

Google Dorks – Google Hacking : exploiter toute la puissance de Google
Sommaire
I. Présentation
Google Dorks, aussi appelé Google Hacking, désigne l'utilisation d'opérateurs de recherche avancés pour extraire des informations publiquement indexées par les moteurs de recherche, en particulier via Google.
Dans ce tutoriel, vous découvrirez les principaux opérateurs (site:, filetype:, intitle:, inurl:, allintext:...), comment combiner ces filtres pour des recherches précises, où trouver des dorks prêts à l'emploi (GHDB) et, surtout, quelles mesures de sécurité appliquer pour réduire les risques d'exposition. Utilisée par les pentesters, analystes OSINT et administrateurs, cette technique permet de mieux exploiter la puissance de Google, mais aussi d'identifier des pages sensibles (pages d'administration, fichiers exposés, sauvegardes, etc.) et d'évaluer la surface d'attaque d'un périmètre web.
Par exemple, les Google Dorks permettent de répondre à la question suivante : Comment trouver des fichiers PDF exposés grâce à Google ? Mais ce n'est qu'un exemple parmi des milliers d'autres.
Avis de non-responsabilité : cet article et cette vidéo sont réalisés à titre éducatif. Je ne serai pas responsable des activités réalisées à partir des connaissances acquises avec ce contenu.
🎥 Disponible au format vidéo :
II. L'indexation des pages et du contenu sur Google
Les moteurs de recherche contiennent des milliards de pages dans leurs index et ces pages sont retournées dans les résultats en fonction de la demande de l'utilisateur. Pour indexer les pages, les moteurs de recherche s'appuient sur ce que l'on appelle des crawlers (mais aussi : agents, bots ou encore robots).
On peut dire que le robot d'un moteur de recherche sait faire deux choses :
- Lire le contenu d'une page et enregistrer son contenu dans la base du moteur de recherche (indexation)
- Suivre les liens contenus dans une page : accès à d'autres pages, qui peuvent être indexées également
Néanmoins, nous avons le pouvoir de dire si "oui" ou "non", on autorise le robot à indexer une page dans sa base. Pour cela, on déploie à la racine de son site Internet ou de son application Web, un fichier nommé "robots.txt". Ce fichier contient les règles d'indexation que doivent appliquer les robots.
Note : l'indexation des pages sur un site Internet s'appuie aussi sur un fichier Sitemap. Ce fichier va servir à déclarer les pages à indexer pour faciliter le travail des robots.
Dans l'exemple ci-dessous, on autorise tous les User-Agent - robots compris - dans tous les répertoires sauf le contenu du répertoire /wp-admin/. Il s'agit d'un répertoire sensible puisqu'il s'agit du répertoire de l'interface d'administration sous WordPress.
User-agent: * Disallow: /wp-admin/
Dans le même esprit, si vous hébergez des PDF sur votre site Web et que vous ne souhaitez pas qu'ils soient indexés, il faudra inclure une règle pour le dire :
User-agent: * Disallow: /*.pdf$
Il existe de nombreux robots d'exploration différents utilisés par les moteurs de recherche, auxquels s'ajoutent les robots utilisés par les IA (ChatGPT, Perplexity, etc.). Par exemple, nous avons :
- Google Images : Googlebot-Image,
- Google : Googlebot,
- Bing : Bingbot,
- Qwant : Qwantify ou Qwant-news
- DuckDuckGo : DuckDuckBot
Grâce au fichier robots.txt évoqué précédemment, on peut gérer les règles pour chaque robot, mais généralement on le fait de façon globale pour rester cohérent. Il est à noter que Google propose un outil en ligne pour tester son fichier "robots.txt" : un bon moyen de tester ses règles.
Vous l'aurez compris, un mauvais lien placé sur une page ou une mauvaise gestion du fichier robots.txt peuvent mener à l'indexation de pages ou de fichiers sensibles avec du contenu confidentiel. C'est là que la notion de Google Dorks entre en jeu !
Grâce aux Google Dorks, nous allons pouvoir trouver des informations cachées mais disponibles car elles sont indexées par Google. Les propriétaires de ces pages ne sont pas au courant qu'elles sont indexées, alors c'est là que ça peut devenir dangereux et préjudiciable !
III. Que peut-on trouver avec les Google Dorks ?
Comme je le disais, avec les Google Dorks on peut exposer l'invisible ! Lorsque l'on effectue une recherche sur Google ou un autre moteur de recherche, on saisit généralement une phrase, par exemple "Qu'est-ce que les Google Dorks ?" ou alors quelques mots clés "définition google dorks". Ensuite, le moteur de recherche nous retourne toutes les pages où il a trouvé ses mots, en classant ses pages par pertinence grâce à ses algorithmes.
Ce sont des requêtes basiques que l'on utilise tous les jours et qui permettent de rechercher de l'information. Quand on parle de Google Hacking, on effectue des recherches avancées que l'on peut associer à une investigation.
On peut trouver tellement de choses différentes qu'il n'est pas possible d'établir une liste exhaustive. Voici tout de même quelques exemples de ce que l'on peut trouver grâce aux Google Dorks :
- Équipements non protégés exposés sur Internet : switchs, caméras, routeurs, imprimantes, etc.
- Fichiers sensibles : liste du personnel, liste d'utilisateurs et mots de passe, etc.
- Fichiers correspondant à des listes de prix (pricelist)
- Pages d'authentification sur des applications Web : espace d'administration d'un site, PhpMyAdmin, etc...
- Serveurs exposés sur Internet et mal configurés, voire pas configurés : page par défaut d'Apache
- Etc...
Lorsque l'on utilise les Google Dorks, on peut effectuer des requêtes avancées pour obtenir une information sans impact réel, mais aussi effectuer des requêtes offensives ou défensives. Les intentions comptent et la notion d'éthique est importante !
Note : nous parlons généralement de Google Dorks mais il faut savoir que les autres moteurs de recherche prennent en charge ces requêtes. Néanmoins, on ne peut pas nier : Google est certainement le moteur de recherche le plus complet et le plus précis, alors il y a tout intérêt à l'utiliser dans le cadre d'une investigation. Mais, cela reste intéressant de comparer les résultats entre plusieurs moteurs de recherche.
IV. Google Dorks - Google Hacking : les opérateurs de recherche
Nos requêtes quotidiennes sont basiques et n'exploitent pas tout le potentiel des moteurs de recherche. Les opérateurs de recherche vont permettre d'exploiter tout le potentiel des moteurs de recherche. C'est le moment d'apprendre à les connaître au travers de quelques exemples.
Reprenons, l'exemple évoqué précédemment avec la requête :
définitions google dorksLorsque l'on saisit cette requête sur Google, on obtient plus de 5 millions de résultats. C'est énorme ! En fait, Google retourne les résultats en prenant les trois mots clés individuellement.
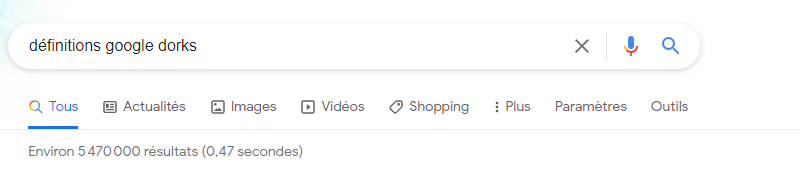
Par contre, si j'effectue la même requête en apportant une légère modification :
définitions "google dorks"Simplement en indiquant des guillemets autour de google dorks, je suis passé de plus de 5 millions de résultats à 253 000 résultats ! Pourquoi ? Lorsque l'on met des guillemets, cela indique au moteur de recherche qu'il doit rechercher la phrase exacte et que le résultat doit inclure cette phrase ! On ne lui demande pas de rechercher "google" et "dorks" dans les pages, mais on lui demande de rechercher "google dorks" : ce qui correspond réellement à ce que l'on cherche. Tandis qu'une page qui contient les mots "google" et "dorks" séparément ne correspondra peut-être pas.
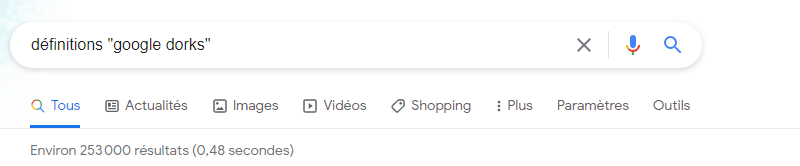
Google prend en charge de nombreux opérateurs de recherche qui vont permettre d'affiner notre requête et d'obtenir des résultats précis. Celui que nous venons de voir est basique, mais il en existe d'autres, bien plus puissants.
Je vous propose une liste de quelques opérateurs de recherche très utiles et couramment utilisés :
- site:
- Rechercher sur un site spécifique / voir les pages indexées pour un site
- Exemple pour le domaine it-connect.fr : site:it-connect.fr
- Rechercher les pages en lien avec Windows Server sur le site it-connect.fr : site:it-connect.fr Windows Server
- filetype:
- Rechercher une extension de fichier spécifique
- Exemple pour rechercher des fichiers PDF associé au mot clé "CV" : filetype:pdf CV
- intitle:
- Rechercher des mots clés dans le titre de la page
- Exemple pour rechercher des pages d'authentification GLPI : intitle:"GLPI - Authentification"
- allintitle
- Similaire à intitle: sauf que l'on veut tous les mots clés dans l'URL
- inurl:
- Rechercher des mots clés dans l'URL de la page
- Exemple pour rechercher des caméras ou des enregistreurs vidéos (DVR) : inurl:/login.rsp
- after:
- Afficher uniquement les résultats référencés après une date spécifique
- Exemple pour prendre le 1er Octobre 2025 comme référence : after:2025-10-01
Il est à noter que plusieurs opérateurs peuvent être utilisés dans la même requête. On peut aussi utiliser plusieurs valeurs possibles pour un même opérateur grâce à la directive "OR" (ou). Par exemple, on peut rechercher les fichiers DOCX et PDF qui contiennent notre nom et notre prénom (à adapter, bien sûr) :
prenom nom filetype:docx OR filetype:pdf
Il y a aussi des mots clés un peu plus fun ! Par exemple, nous avons "movie:" qui permet de rechercher des films avec un acteur spécifique.
movie:will smith
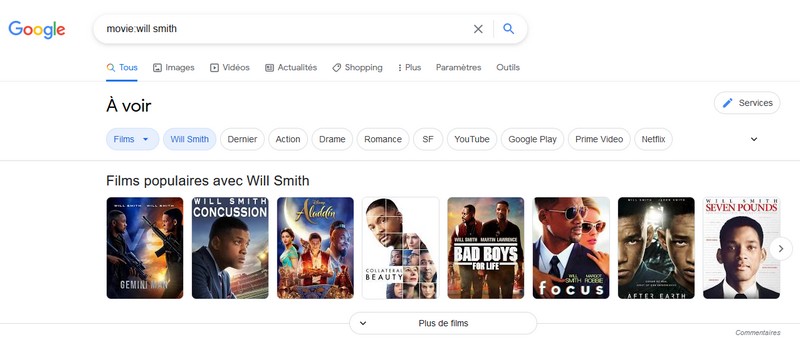
V. Exemples Google Dorks - Google Hacking : GHDB
Avant toute chose, pour effectuer vos requêtes basées sur les Google Dorks, je vous recommande d'utiliser le navigateur Tor (Tor Browser) ou une connexion VPN. Même si, dans de nombreux cas, Google bloquera vos requêtes car il n'apprécie pas trop l'usage de Tor. Enfin, si vous pensez que c'est nécessaire vis-à-vis de la recherche que vous allez faire ! Pour une simple requête, agir dans une fenêtre de navigation privée me semble suffisant.
On pourrait inventer nos propres requêtes par rapport à ce que l'on a vu précédemment, mais sachez que le site exploit-db.com contient une section nommée "Google Hacking Database" (GHDB) : elle contient plus de 6 500 requêtes Google Dorks différentes ! Elle est régulièrement mise à jour par la communauté du site. Un véritable moteur de recherche pour Google Dorks !
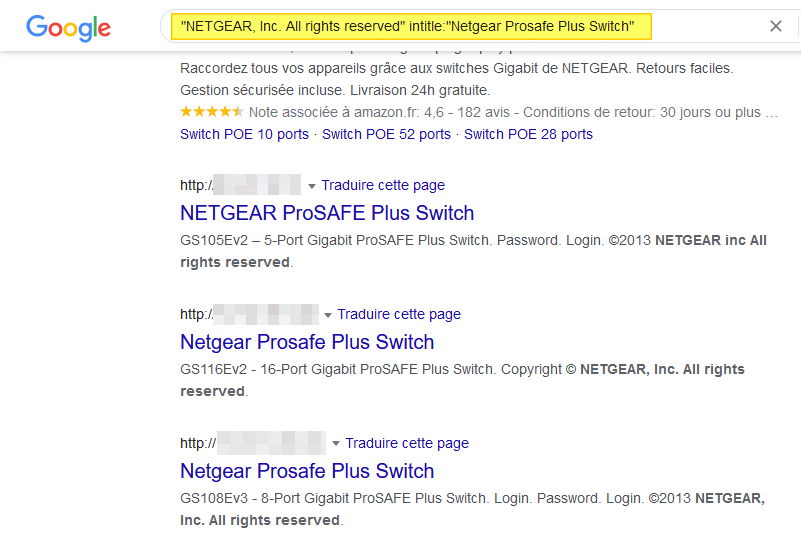
Pour cet exemple, je vais prendre une requête qui permet de rechercher des switchs NETGEAR référencé sur Google : je n'ai rien contre NETGEAR. Surtout, je tiens à préciser que ce cas de figure n'est pas propre à NETGEAR car on peut trouver des pages pour de nombreux fabricants (le problème ne vient pas du fabricant...).
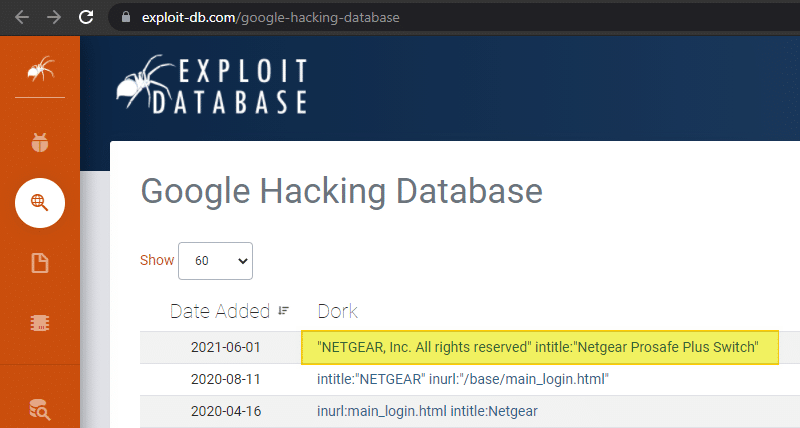
On va tout simplement aller sur Google et saisir la requête Dork indiquée sur le site exploit-db.com. Cette requête retourne 282 résultats, tout de même !
À quoi correspondent-ils ? Il s'agit d'interfaces d'administration de switchs NETGEAR, référencées sur Google ! L'URL est en fait l'adresse IP publique sur laquelle le switch est accessible. Certains switchs sont inaccessibles tandis que pour d'autres, cela fonctionne !
Imaginons un switch exposé de cette façon, qui serait en plus vulnérable à des failles de sécurité, on pourrait prendre la main dessus, etc.... Derrière, cela peut être lourd de conséquences pour l'entreprise. On peut aussi être beaucoup plus gentil et chercher à rentrer en contact avec le propriétaire du switch pour l'avertir et lui éviter des ennuis ! L'ETHIQUE !
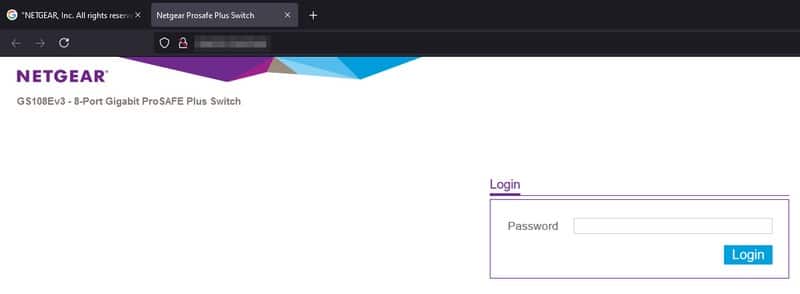
Tiens, celui-ci fonctionne.... Je me retrouve connecté sur l'interface d'administration d'un switch !
Lorsqu'un équipement est référencé dans Google, l'adresse du site correspond à l'adresse IP. Pour savoir si vous avez un équipement référencé sur Google, vous pouvez effectuer la requête suivante :
site:X.X.X.X
Où X.X.X.X correspond à votre adresse IP publique. Si vous en avez plusieurs, il faudra répéter l'opération.
Si vous utilisez WordPress, vous pourriez vérifier également que votre interface d'administration n'est pas référencée dans Google :
inurl:/wp-admin/ site:<votre domaine>
Je vous encourage à utiliser les exemples de la base GHDB pour bien appréhender la syntaxe des opérateurs et cette notion de Google Dorks.
En complément, voici quelques requêtes sélectionnées :
- Rechercher les serveurs Web Apache2 avec une page par défaut
# Ubuntu intitle:"Apache2 Ubuntu Default Page: It works" # Debian intitle:"Apache2 Debian Default Page: It works"
- Rechercher des switchs Dell OpenManage
intitle:"Dell OpenManage Switch Administrator" intext:"Type in Username and Password, then click OK"
- Rechercher des pages de statut de caméra (configuration de la caméra)
intitle:"Camera Status" inurl:/control/
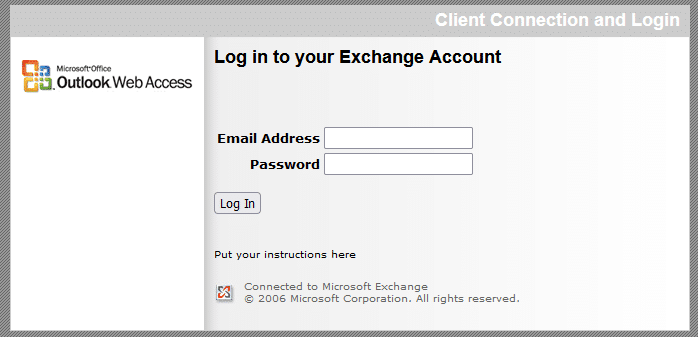
- Rechercher des pages de connexion sur un Webmail Exchange
site:exchange.*.*/owa/ ou intitle:"Exchange Log In"
C'est quand même drôle de tomber là-dessus :
Pour finir, je souhaitais partager avec vous un dernier exemple ! Bien que ce soit pas lié directement à la sécurité, sachez qu'il est possible d'obtenir des catalogues de prix appelés "pricelist" grâce à un moteur de recherche. Cela ne fonctionne pas pour tous les fabricants, mais on peut obtenir des fichiers Excel plus ou moins récents avec des prix de matériel, ce qui donne toujours une indication ! Par exemple :
pricelist dell filetype:xlsx

Note : restez vigilant pendant vos recherches, notamment lorsque vous téléchargez des fichiers depuis un site.
VI. Conclusion
Les Google Dorks sont un outil puissant pour la découverte d'informations publiques ! En tant que professionnel, adoptez une démarche responsable : testez vos propres périmètres, utilisez les dorks pour auditer, et corrigez les fuites éventuelles (robots.txt, balises noindex, authentification). Enfin, il est préférable d'alerter les responsables lorsque vous trouvez des données sensibles : prévenir vaut mieux que guérir.
Même dans le cadre des recherches quotidiennes, les Google Dorks peuvent s'avérer très utiles car c'est une manière très puissante d'affiner les résultats de votre requête. Pour aller plus loin, il existe des outils pour utiliser les Google Dorks, je pense notamment à DorkMe et à PaGoDo (Passive Google Dorks).
Maintenant à vous de passer à l'action avec une session de Dorking défensive pour identifier les éventuelles vulnérabilités qui pourraient affecter votre propre site Internet, vos propres serveurs ou vos propres équipements.
Qu'est‑ce qu'un Google Dork et à quoi ça sert ?
Un Google Dork est une requête avancée exploitant des opérateurs de recherche (ex. filetype:pdf site:domaine.fr) pour trouver des contenus indexés précisément. Les pentesters et analystes OSINT les utilisent pour détecter des informations publiées volontairement ou involontairement.
Quelle est la différence entre robots.txt et noindex ?
robots.txt indique aux robots ce qu'ils peuvent ou ne peuvent pas crawler sur un site web ou un service en ligne. Ce n'est pas un mécanisme fiable pour empêcher l'indexation. noindex (ou une authentification) est préférable pour empêcher l'apparition d'une page dans Google.
Où trouver des Google Dorks prêts à l'emploi ?
La Google Hacking Database (GHDB) sur Exploit‑DB centralise des milliers de dorks classés par type (fichiers, panneaux d'administration, bases de données, etc.). C'est une très belle ressource à utiliser dans le respect de la loi. Vous pouvez aussi trouver des exemples dans cet article.
Que faire si je trouve des données sensibles ?
Ne les exploitez pas. Documentez (captures, URLs), notifiez le propriétaire via un canal officiel (security@, formulaire de contact) et, si nécessaire, suivez une procédure de divulgation responsable. L'éthique est importante.










Bonjour,
J’aime bien votre site. Je ne sais pas comment je suis arrivé dessus car je n’arrive jamais à le retrouver… 😀
Va falloir faire un effort de référencement 😉
En tout cas il est maintenant dans mes favoris au travail et chez moi (et je partage autant que faire se peut).
Bon courage et encore merci pour votre partage.
Hello Pierre,
Pourtant le site est bien référencé (enfin je crois ahah) et en général on trouve facilement les articles. J’avoue que ta remarque me surprend un petit peu :-p
Merci pour ton soutien en tout cas, et à bientôt ! 🙂
Florian
le fichier robots.txt n’empêche pas l’indexation, il empêche l’exploration. si vous ne voulez pas être indexé, il faut le header http X-Robots-Tag « noindex, nofollow ».
Bonjour, une phrase m’a fait pleurer du sang. Je vous la mets ici pour éviter d’autres accidents 🙂 « Les intentions comptes… »
Très bel article.
Merci
Bonjour,
Merci je vais corriger la faute… 🙂
Très bon article, ça rappelle à quel point une simple recherche Google peut révéler bien plus que ce qu’on imagine… surtout quand des pages sensibles sont indexées sans que personne ne s’en rende compte.
Les exemples de la GHDB sont toujours un peu flippants, mais vraiment utiles pour comprendre ce qu’un pentester (ou un curieux) peut trouver en quelques requêtes.
Ça donne envie de faire un petit audit de son propre domaine, juste pour vérifier qu’aucune page “oubliée” ne traîne dans l’index.
D’ailleurs, vous conseillez plutôt de commencer par un scan manuel avec quelques dorks classiques, ou carrément d’utiliser un outil automatisé pour détecter ce qui fuite ?